Нечёткая логика – логика, основанная на теории нечётких множеств. Её предметом является построение моделей приближенных рассуждений человека и использование их в компьютерных системах. В нечёткой логике расширена граница оценки с двузначной (Либо 0, либо 1) до неограниченной многозначной оценки (На интервале ).
Нечёткое множество A в полном пространстве X определяется через функцию принадлежности m A (x):

Логика определения понятия нечёткого множества не содержит какой-либо нечёткости. Вместо указания какого-то конкретного значения (Например 0.8) обычно с помощью нижних и верхних значений задают допустимые пределы оценки (Например ).
В случае нечёткой логики можно создать неограниченное число операций, поэтому в ней не используются базовые операции для записи остальных. Особо важное значение имеют расширения НЕ, И, ИЛИ до нечётких операций. Они называются соответственно – нечёткое отрицание, t-норма и s-норма. Так как число состояний неограниченно, то невозможно описать эти операции с помощью таблицы истинности. Операции поясняются с помощью функций и аксиом, а представляются с помощью графиков.
Аксиоматическое представление нечётких операций:
Нечёткое отрицание

Аксиома N1 сохраняет свойство двузначного НЕ, а N2 – сохраняет правило двойного отрицания. N3 – наиболее существенная: нечёткое отрицание инвертирует последовательность оценок.

Типичная операция нечёткого отрицания – вычитание из 1.
При отрицании значение 0.5 является центральным и обычно x и x θ принимают симметричные значения относительно 0.5.
T-норма.

Аксиома T1 справедлива, как и для чёткого И. T2 и T3 – законы пересечения и объединения. Аксиома T4 является требованием упорядоченности.
Типичной t-нормой является операция min или логическое произведение:

При логическом произведении график строится симметрично относительно плоскости, образуемый наклонными x1 и x2.
S-норма.

Типичной s-нормой является логическая сумма, определяемая операцией max.
![]()
Кроме неё существуют алгебраическая сумма, граничная сумма и драстическая сумма:


Как видно из рисунков порядок обратный, нежели в случае t-нормы.
В качестве примеров нечёткого определения можно рассмотреть температуру и работу клапана:

Сходства
Нечёткая логика является обобщением классической чёткой логики. И чёткая и нечёткая логики основаны на множествах и на операциях отношения. Нечёткие операции являются расширением операций чёткой логики.
Различия
В чёткой логике переменные являются полными членными множеств, а в нечёткой – только частичными членами множеств.
В чёткой логике утверждение либо истинно, либо ложно, в ней действует закон исключения среднего. В нечёткой логике истинность или ложность перестают быть абсолютными и утверждения могут быть частично истинными и частично ложными. В чёткой логике число возможных операций конечно и зависит от количества входов, тогда как в нечёткой логике число возможных операций бесконечно.
3. Пример
Сначала мы рассмотрим множество X всех вещественных чисел между 0 и 10, которые мы назовем областью исследования. Теперь, давайте определим подмножество X всех вещественных чисел в амплитуде между 5 и 8.
A =
Теперь представим множество A с помощью символической функции, т.е. эта функция приписывает число 1 или 0 к каждому элементу в X , в зависимости от того, находится ли элемент в подмножестве А или нет. Это приводит к следующей диаграмме:

Мы можем интерпретировать элементы, которым назначено число 1, как элементы которые находятся в множестве А, и элементы, которым назначено число 0, как элементы не в множестве A .
Этой концепции достаточно для многих областей приложений. Но мы можем легко найти ситуации, где теряется гибкость. Чтобы показать это рассмотрим следующий пример, показывающий отличие нечёткого множества от чёткого:
В этом примере мы хотим описать множество молодых людей. Более формально мы можем обозначить
B = {множество молодых людей}
Поскольку, вообще, возраст начинается с 0, нижняя граница этого множества должна быть нулевой. Верхнюю границу, с другой стороны, надо определить. На первый раз определим верхнюю границу множества, скажем, 20 лет. Следовательно, мы получаем B как четкий интервал, а именно:
B =
Теперь возникает вопрос: почему кто-то на его 20-ом дне рождения молодой, а на следующий день не молодой? Очевидно, это - структурная проблема, поскольку, если мы перемещаем верхнюю границу от 20 до произвольной точки, мы можем излагать тот же самый вопрос.
Более естественный способ описать множество B состоит в том, чтобы ослабить строгое разделение между молодыми и не молодыми. Мы будем делать это, допуская не только (четкое) решение ДА: он/она находится в множестве молодых , или НЕТ: он/она не в множестве молодых , но более гибких фраз подобно: Хорошо, он/она принадлежит немного больше к множеству молодых или НЕТ, он/она почти не принадлежит к множеству молодых.
В нашем первом примере мы кодировали все элементы Области Исследования 0 или 1. Прямой путь обобщить эту концепцию для нечёткого множества состоит в том, чтобы определить большее количество значений между 0 и 1. Фактически, мы определяем бесконечно многие варианты между 0 и 1, а именно единичный интервал I = .
Интерпретация чисел в нечётком множестве, назначенная всем элементам Области Исследования, более трудная. Конечно, снова число 1 назначено элементу как способ определить элемент, который находится в множестве B и 0 - способ, при котором элемент не определен в множестве B . Все другие значения означают постепенную принадлежность к множеству B .
Для большей наглядности, теперь мы показываем множество молодых, подобно нашему первому примеру, графически при помощи символической функции.

При таком способе 25-летние люди будут все еще молоды на 50 процентов (0.5). Теперь Вы знаете, что такое нечеткое множество.
Судьба нечеткой логики, как нового научного направления, сходна с ее содержимым - необычна, сложна и парадоксальна. В основе нечеткой логики лежит теория нечетких множеств, изложенная в серии работ Заде в 1965-1973 годах.
Параллельно с разработкой теоретических основ новой науки, Заде прорабатывал различные возможности ее практического применения. И в 1973 году эти усилия увенчались успехом - ему удалось показать, что нечеткая логика может быть положена в основу нового поколения интеллектуальных систем управления.
Однако основные результаты использования нечеткой логики были получены в Японии. Японцы довели практическое воплощение нечеткой логики до совершенства, но применяли её в основном в изделиях массового рынка – бытовая техника и т.п.
Особенно, конечно же, хочется отметить программное обеспечение, основанное на принципах нечеткой логики и нечетких множеств, которое активно применяется в финансовых и экономических сферах деятельности человека.
Примеры программ на основе нечеткой логики
1. CubiCalc представляет собой своего рода экспертную систему, в которой пользователь задает набор правил типа "если - то", а система пытается на основе этих правил адекватно реагировать на изменение ситуации. Вводимые правила содержат нечеткие величины, т.е. имеют вид "если Х принадлежит А, то Y принадлежит В", где А и В - нечеткие множества. Например: "Если этому жулику удастся сохранить популярность в регионах, то его шансы на выборах будут весьма высоки". Здесь использованы два нечетких термина - "популярность" и "вероятность избрания", которые практически невозможно задать точным значением, но сравнительно легко отобразить функцией распределения. И аппарат нечеткой логики, заложенный в CubiCalc, дает вам изумительную возможность впоследствии оперировать этими понятиями как точными и строить на их основе целые логические системы, не заботясь о нечеткой природе исходных определений.
CubiCalc и сегодня остается одним из самых продаваемых пакетов на основе нечеткой логики.
2. FuziCalc фирмы FuziWare - это первая в мире электронная таблица, позволяющая работать как с точными числовыми значениями, так и с приблизительными, "нечеткими" величинами.
Если в процессе вычислений вы использовали нечеткие величины, результат также будет иметь вид функции распределения. Однако в любом случае результат будет получен! И он будет точнее и достовернее, чем при использовании любых других доступных вам методов.
3. Триумф-Аналитика - это программа для оперативного и стратегического управления предприятием оптовой и розничной торговли, супермаркетом, сбытовой сетью. Сегодня Триумф-Аналитика - единственный аналитический продукт на российском рынке, предоставляющий возможности анализа, прогноза и оптимизации торговой деятельности. Назначение пакета - дать руководителю торгового предприятия полную и точную картину его бизнеса, быстро выявить скрытые резервы и, в конечном итоге, увеличить доходность и снизить издержки своей фирмы.
Триумф-Аналитика - продукт Корпорации "Парус", разработанный по заказу Корпорации специалистами Национального Альянса Управляющих, Консультантов и Аналитиков. В основу программы легли мощные аналитические алгоритмы, используемые при создании Ситуационных центров крупных корпораций, региональных руководителей.
В пакете Триумф-Аналитика использованы самые современные технологии анализа, прогнозирования и ситуационного моделирования - нейронные сети, нечеткая логика, системная динамика. Использованные в программе технологии не могут быть реализованы неспециалистом, а без их применения качество анализа и прогнозов будет неудовлетворительным. Продукт получился: легким, быстрым, гибким, мощным.
Он позволяет быстро диагностировать все основные виды ошибок в управлении торговым предприятием.
Использование самых современных средств разработки программного продукта и базы данных позволило добиться уникальных характеристик по мощности и быстродействию. Так, экспресс-анализ деятельности крупной оптовой компании за квартал средствами комплекса Триумф-Аналитика занимает менее 30 минут.
4. AnyLogic - первый и единственный инструмент имитационного моделирования, объединивший методы системной динамики, "процессного" дискретно-событийного и агентного моделирования в одном языке и одной среде разработки моделей.
Гибкость AnyLogic позволяет отражать динамику сложных и разнородных экономических и социальных систем на любом желаемом уровне абстракции. AnyLogic включает набор примитивов и объектов библиотек для эффективного моделирования производства и логистики, бизнес-процессов и персонала, финансов, потребительского рынка, а также окружающей инфраструктуры в их естественном взаимодействии. Объектно-ориентированный подход, предлагаемый AnyLogic, облегчает итеративное поэтапное построение больших моделей.
В редакторе AnyLogic Вы можете разработать анимацию и интерактивный графический интерфейс модели. Редактор поддерживает большой набор фигур, элементов управления (кнопок, ползунков, полей ввода и т.д.), импорт растровой графики и векторной графики в формате DXF. Анимация может быть иерархической и поддерживать несколько перспектив. Например, Вы можете определить глобальный взгляд на процесс производства с несколькими агрегированными индикаторами, а также детальные анимации конкретных операций - и переключаться между ними.
В AnyLogic включены средства анализа данных и большой набор элементов бизнес-графики, спроектированных для эффективной обработки и презентации результатов моделирования: статистики, наборы данных, графики, диаграммы, гистограммы.
AnyLogic поддерживает множество разнообразных типов экспериментов с моделями: простой прогон, сравнение прогонов, варьирование параметров, анализ чувствительности, оптимизация, калибровка, а также произвольный эксперимент по пользовательскому сценарию.
5. ITHINK предоставит Вам принципиально новые возможности, которые выходят далеко за рамки разработки стандартных форм документов. Он способен придать Вашим плановым и проектным разработкам новое качество. Программный пакет ITHINK - уникальное средство имитационного моделирования производственных и финансовых проектов и процессов.
В начале 90-х пакет ITHINK стал признанным стандартом структурного моделирования на Западе. Он широко используется в интеллектуальных центрах корпораций, банках, правительственных структурах и проектно-исследовательских учреждениях. В глазах зарубежного инвестора инвестиционный проект, разработанный с использованием системы ITHINK, приобретает дополнительные выигрышные характеристики. Работа с этим элитарным инструментом свидетельствует об определенной “приобщенности” разработчиков к новейшим наиболее тонким технологиям анализа проектов.
С помощью ITHINK решались разнообразные задачи, начиная от анализа причин разрушения дамбы в Юго-Восточной Азии в 1989г. и кончая обслуживанием и распределением пациентов, поступающих в приемный покой клиники. Однако в наибольшей степени ему органичны так называемые “потоковые” задачи. Они охватывают весьма широкую группу ситуаций, встречающихся в повседневной жизни предпринимателей, менеджеров и экспертов в области бизнес-планирования. Дело в том, что большинство развивающихся во времени явлений можно представить как потоковые процессы.
Пакет ориентирован на широкую группу пользователей - от руководителей, решающих сложные управленческие проблемы, до специалистов в области ценных бумаг, консультационных компаний и индивидуальных предпринимателей и исследователей.
6. PolyAnalyst предназначается для получения аналитической информации путем автоматической обработки исходных данных и может использоваться аналитиками, занятыми в различных областях деятельности.
Пакет PolyAnalyst - система, в основу которой положена технология искусственного интеллекта Data Mining. При обработке исходных данных она позволяет обнаруживать многофакторные зависимости, которым придает затем вид функциональных выражений (класс функций в них практически произволен), можно также строить структурные и классификационные правила. При этом анализу подвергаются исходные данные различных типов: действительные числа, логические и категориальные величины. Выводимые правила принимают вид либо функций, либо циклов, либо условных конструкций.
Очень важно, что при работе с пакетом PolyAnalyst аналитику не нужно допускать какие-либо закономерности в данных, за него это сделает программа анализа. Разумеется, пользователь не устраняется полностью из процесса анализа данных - от него, конечно же, требуется указать зависимую и независимую переменные, роль которых играют поля записей в исследуемой базе данных.
Система PolyAnalyst состоит из двух частей. Первая из них - модуль универсальной предварительной обработки данных ARNAVAC. Методы, реализованные в этом модуле, традиционны для автоматизации аналитической обработки данных. ARNAVAC обнаруживает в массивах данных функционально связные кластеры, фильтрует шум и случайные выбросы. Затем автоматический аналитик строит многомерную линейную регрессионную зависимость, как наиболее простое и доступное описание исходных данных, используя при этом универсальный быстродействующий алгоритм, автоматически выбирающий наиболее влияющие параметры с корректным определением их значимости.
Процесс построения гипотез идет автоматически, независимо от их сложности.
7. ExPro Master реализует интуитивно очевидную логику решения человеком аналитических задач оценки, прогнозирования и классификации, которая хорошо согласовывается с общепринятыми принципами исследования сложных систем и, поэтому, может рассматриваться как конструктив решения широкого круга системных задач.
Структура решения отдельной экспертно-аналитической задачи включает в себя следующие основные информационные компоненты:
Концептуальную модель предметной области экспертно-аналитической задачи или систему предпочтений, которая является формализованным представлением эксперта о задаче, ее элементах и связях; - оценки объектов из предметной области или просто объекты реального мира, которые анализируются при решении задачи;
Внешние факторы динамики, представленные в виде статистических данных (которые описывают состояние концептуальной модели и объектов в прошлом) и факторы будущего (которые описывают возможные изменения концептуальной модели и объектов в будущем);
Корректуры или внутренние факторы динамики, которые порождаются самой концептуальной моделью по установленным правилам.
Система предпочтений является важнейшей составляющей экспертно-аналитической задачи и предназначена для формализованного представления осознанных знаний эксперта о структуре, связях и характеристиках элементов предметной области решаемой задачи. Система предпочтений представляется в виде множества вершин и направленных связей между ними. Вершины системы предпочтений описывают понятия, которые задаются экспертом и несут конкретную смысловую нагрузку, зависящую от задачи. Эти понятия, в свою очередь, определяются через другие понятия при помощи связей. Связи можно рассматривать как отношения, которые задают влияние одних понятий на другие.
Для формализации связей понятий системы предпочтений в программном комплексе используется конструктив нечеткой меры по Сугено, которая для каждого контекста каждого понятия задается на множестве его частных понятий. Другими словами, к каждой вершине приписывается несколько нечетких мер по числу ее контекстов. Действительно, любое понятие может иметь различный смысл в различных контекстах.
Нечеткие меры также владеют одним чудесным свойством. Они поддерживают понятие модальности экспертных оценок и могут формализовать не только предпочтения в вершинах системы предпочтений, но и указывать семантический оттенок этих предпочтений (возможно, очень возможно, вероятно, необходимо и так далее). Влияние семантического оттенка настолько велико, что в некоторых случаях может приводить к обратным результатам, что в полной мере подтверждается существующей практикой.
Использование нечетких мер для представления экспертных знаний является отличительной особенностью и достоинством программного комплекса.
Внешние факторы динамики являются одной из основных компонент программного комплекса, которая определяет изменчивость во времени как системы предпочтений, так и оценок объектов. Внешние факторы динамики могут иметь различную физическую природу. Как один из вариантов может быть рассмотрено действие некоторых внешних событий по отношению к исследуемой системе.
Таким образом, внешние факторы динамики являются той составляющей программного комплекса, которая обеспечивает динамику решений в экспертно-аналитических задачах в зависимости от изменения внешних условий функционирования системы.
Корректуры или внутренние факторы динамики также являются одной из основных компонент программного комплекса, которая определяет изменчивость во времени как системы предпочтений, так и оценок объектов. В отличие от внешних, внутренние факторы порождаются самой системой предпочтений на основе оценки состояния одного из объектов в заданные моменты времени. Действие корректур направлено также на контекст вершины или на характеристику объекта. На них также могут влиять несколько корректур, каждая со своей важностью. Корректуры совместно с внешними факторами, образуют единое поле влияний.
8. МаркетЭффект предназначено для выработки эффективных маркетинговых решений коммерческими и государственными предприятиями среднего и крупного масштаба в сфере производства, торговли, оказания услуг. Оно направлено на решение задач, связанных с продвижением (продажей) товаров на рынок, с закупками сырья, материалов, энергоресурсов и т.п.
Приложение функционирует в составе системы FinExpert разработки компании IDM. Учетные данные по объемам продаж (покупок), накапливаемые системой FinExpert, служат в МаркетЭффект исходной точкой для анализа рынка (спроса, предложения, цен).
Приложение ориентировано на руководящий состав предприятий, персонал их служб управления, маркетинга и сбыта, на всех, кто принимает участие в выработке стратегии действий предприятия на рынке.
МаркетЭффект позволяет решать следующие задачи:
Анализ рынка.
Анализ и прогноз продаж (покупок).
Прогнозирование эффективности и рисков.
Планирование и анализ маркетинга.
Поиск эффективных схем и стратегий.
Решение этого спектра задач основано на использовании учетной информации системы FinExpert, данных, импортируемых из других компьютерных программ, а также информации, вводимой непосредственно пользователем приложения МаркетЭффект ; построено на базе нечеткой технологии (fuzzy technology). Это позволяет решать задачи, возложенные на приложение, и обрабатывать весь возможный спектр исходной информации на общей идеологической и инструментальной основе и не ограничиваться при этом использованием только точных, числовых данных о состоянии рынка. Приложение позволяет дополнительно учитывать также очень ценные знания специалистов о рынке и предположения о его развитии, несмотря на то, что эта информация имеет описательный, часто нечисловой, нечеткий характер.
Динамика развития рынка определяется множеством факторов, зависящих от сектора рынка, макроэкономических процессов, активности конкурентов, предпочтений покупателей и т.д. Эти же факторы, в свою очередь, оказывают влияние на работу предприятия, на величины его постоянных и переменных издержек, могут нарушать равновесие в секторе рынка.
Для оптимизации принимаемых решений на предприятии проектируются альтернативные схемы и стратегии, влияющие на изменение эффективности и рисков конкретно анализируемого проекта или их совокупности, и проводятся соответствующие расчеты с учетом прогнозного изменения рыночной ситуации. На основании полученных решений в соответствии с определенной системой предпочтений, отвечающей потребностям предприятия, осуществляется оценка альтернативных схем и стратегий и выбор наиболее эффективного решения.
Использование fuzzy-технологии позволяет получать диапазоны прогнозных значений величин в соответствии с определенной долей уверенности.
Поэтому пользователь приложения всегда имеет возможность оценить степень риска как анализируемого проекта в целом, так и его отдельных показателей.
9. Fuzzy Estimation of Critical Messages (FECM) предназначен для оценки интегрального (совокупного) влияния потока сообщений, поступающих в большом количестве накануне и в процессе валютных торгов, на курсы валют. Как результат - прогнозы этих курсов. Совместно с имеющимися программными продуктами технического анализа, использование FECM позволяет соединить прошлое и будущее при прогнозировании курсов валют и, тем самым, повысить возможность принятия правильных решений участниками валютных торгов и других сфер бизнеса.
Использование программы - прогнозирование и системный анализ фундаментальных факторов при проведении валютных торгов на рынке FOREX.
2.1 Основные понятия нечеткой логики
Как было упомянуто в предыдущих главах, классическая логика оперирует только двумя понятиями: «истина» и «ложь», и исключая любые промежуточные значения. Аналогично этому булева логика не признает ничего кроме единиц и нулей.
Нечеткая же логика основана на использовании оборотов естественного языка. Человек сам определяет необходимое число терминов и каждому из них ставит в соответствие некоторое значение описываемой физической величины. Для этого значения степень принадлежности физической величины к терму (слову естественного языка, характеризующего переменную) будет равна единице, а для всех остальных значений ‒ в зависимости от выбранной функции принадлежности.
При помощи нечетких множеств можно формально определить неточные и многозначные понятия, такие как «высокая температура», «молодой человек», «средний рост» либо «большой город». Перед формулированием определения нечеткого множества необходимо задать так называемую область рассуждений (universe of discourse). В случае неоднозначного понятия «много денег» большой будет признаваться одна сумма, если мы ограничимся диапазоном и совсем другая–в диапазоне .
Лингвистические переменные:
Лингвистической переменной является переменная, для задания которой используются лингвистические значения, выражающие качественные оценки, или нечеткие числа. Примером лингвистической переменной может быть скорость или температура, примером лингвистического значения - характеристика: большая, средняя, малая, примером нечеткого числа - значение: примерно 5, около 0.
Лингвистическим терм-множеством называется множество всех лингвистических значений, используемых для определения некоторой лингвистической переменной. Областью значений переменной является множество всех числовых значений, которые могут принимать определенный параметр изучаемой системы, или множество значений, существенное с точки зрения решаемой задачи.
Нечеткие множества:
Пусть
‒ универсальное множество, ‒
элемент, а
‒
элемент, а ‒
некоторое свойство. Обычное (четкое)
подмножество
‒
некоторое свойство. Обычное (четкое)
подмножество универсального множества
универсального множества , элементы которого удовлетворяют
свойству
, элементы которого удовлетворяют
свойству ,
определяются как множество упорядоченных
пар
,
определяются как множество упорядоченных
пар ,где
,где ‒ характеристическая функция, принимающая
значение 1, если удовлетворяет свойству, и 0 - в противном случае.
‒ характеристическая функция, принимающая
значение 1, если удовлетворяет свойству, и 0 - в противном случае.
Нечеткое
подмножество отличается от обычного
тем, что для элементов
 из
из нет однозначного ответа ”да-нет”
относительно свойства. В связи с этим,
нечеткое подмножество универсального
множества
нет однозначного ответа ”да-нет”
относительно свойства. В связи с этим,
нечеткое подмножество универсального
множества определяется как множество упорядоченных
пар
определяется как множество упорядоченных
пар ,
где
,
где ‒ характеристическая функция
принадлежности, принимающая значения
в некотором упорядоченном множестве
(например,
‒ характеристическая функция
принадлежности, принимающая значения
в некотором упорядоченном множестве
(например, ).
Функция принадлежности указывает
степень принадлежности элемента
).
Функция принадлежности указывает
степень принадлежности элемента множеству
множеству .
Множество
.
Множество называют множеством принадлежностей.
Если
называют множеством принадлежностей.
Если ,
то нечеткое множество может рассматриваться
как обычное четкое множество.
,
то нечеткое множество может рассматриваться
как обычное четкое множество.
Множество
элементов пространства  ,
для которых
,
для которых  ,
называется носителем нечеткого множества
,
называется носителем нечеткого множества
 и обозначается supp
A
:
и обозначается supp
A
:
Высота
нечеткого множества
 определяется как
определяется как
Нечеткое
множество
 называется нормальным тогда и только
тогда, когда
называется нормальным тогда и только
тогда, когда .
Если нечеткое множество
.
Если нечеткое множество не является нормальным, то его можно
нормализовать при помощи преобразования
не является нормальным, то его можно
нормализовать при помощи преобразования
 ,
,
где
 ‒ высота этого множества.
‒ высота этого множества.
Нечеткое
множество ,
является выпуклым тогда и только тогда,
когда для произвольных
,
является выпуклым тогда и только тогда,
когда для произвольных и
и выполняется
условие
выполняется
условие
2.1.1 Операции над нечеткими множествами
Включение.
Пусть
 и
и ‒ нечеткие множества на универсальном
множестве
‒ нечеткие множества на универсальном
множестве .
Говорят, что
.
Говорят, что содежится в
содежится в ,
если
,
если
Равенство. и равны, если
Дополнение.
Пусть
 ,
, и
и ‒ нечеткие множества, заданные на
‒ нечеткие множества, заданные на .
. и
и дополняют
друг друга, если.
дополняют
друг друга, если.
Пересечение.
 ‒
наибольшее нечеткое подмножество,
содержащееся одновременно в
‒
наибольшее нечеткое подмножество,
содержащееся одновременно в и
и :
:
Объединение.
 ‒ наибольшее нечеткое подмножество,
содержащее все элементы из
‒ наибольшее нечеткое подмножество,
содержащее все элементы из и
и :
:
Разность.
 ‒ подмножество с функцией принадлежности:
‒ подмножество с функцией принадлежности:
2.1.2 Нечеткие отношения
Пусть
 ‒
прямое произведение универсальных
множеств и
‒
прямое произведение универсальных
множеств и ‒
некоторое множество принадлежностей.
Нечеткое n-арное отношение определяется
как нечеткое подмножество
‒
некоторое множество принадлежностей.
Нечеткое n-арное отношение определяется
как нечеткое подмножество на
на , принимающее свои значения в
, принимающее свои значения в .
В случае
.
В случае и
и нечетким отношением
нечетким отношением между
множествами
между
множествами и
и будет
называться функция
будет
называться функция ,
которая ставит в соответствие каждой
паре элементов
,
которая ставит в соответствие каждой
паре элементов величину
величину .
.
Пусть

‒ нечеткое отношение
‒ нечеткое отношение между
между и
и , и
, и нечеткое отношение
нечеткое отношение между
между и
и .
Нечеткое отношение между
.
Нечеткое отношение между и
и ,
обозначаемое
,
обозначаемое ,
определенное через
,
определенное через и
и выражением,
называется композицией отношений
выражением,
называется композицией отношений и
и .
.
Нечеткая импликация.
Нечеткая
импликация представляет собой правило
вида: ЕСЛИ
 ТО
ТО ,где
,где – условие, а
– условие, а – заключение, причем
– заключение, причем и
и ‒ нечеткие множества, заданные своими
функциями принадлежности
‒ нечеткие множества, заданные своими
функциями принадлежности ,
, и областями определения
и областями определения ,
, соответственно. Обозначается импликация
как
соответственно. Обозначается импликация
как .
.
Различие между классической и нечеткой импликацией состоит в том, что в случае классической импликации условие и заключение могут быть либо абсолютно истинными, либо абсолютно ложными, в то время как для нечеткой импликации допускается их частичная истинность, со значением, принадлежащим интервалу . Такой подход имеет ряд преимуществ, поскольку на практике редко встречаются ситуации, когда условия правил удовлетворяются полностью, и по этой причине нельзя полагать, что заключение абсолютно истинно.
В нечеткой
логике существует множество различных
операторов импликации. Все они дают
различные результаты, степень эффективности
которых зависит в частности от моделируемой
системы. Одним из наиболее распространенных
операторов импликации является оператор
Мамдани, основанный на предположении,
что степень истинности заключения не может быть выше степени выполнения
условия
не может быть выше степени выполнения
условия :
:
2.2 Построение нечеткой системы
Из разработок искусственного интеллекта завоевали устойчивое признание экспертные системы, как системы поддержки принятия решений. Они способны аккумулировать знания, полученные человеком в различных областях деятельности. Посредством экспертных систем удается решить многие современные задачи, в том числе и задачи управления. Одним из основных методов представления знаний в экспертных системах являются продукционные правила, позволяющие приблизиться к стилю мышления человека. Обычно продукционное правило записывается в виде: «ЕСЛИ (посылка) (связка) (посылка)… (посылка) ТО (заключение)».Возможно наличие нескольких посылок в правиле, в этом случае они объединяются посредством логических связок «И», «ИЛИ».
Нечеткие системы (НС) тоже основаны на правилах продукционного типа, однако в качестве посылки и заключения в правиле используются лингвистические переменные, что позволяет избежать ограничений, присущих классическим продукционным правилам.
Таким образом, нечеткая система - это система, особенностью описания которой является:
нечеткая спецификация параметров;
нечеткое описание входных и выходных переменных системы;
нечеткое описание функционирования системы на основе продукционных «ЕСЛИ…ТО…»правил.
Важнейшим классом нечетких систем являются нечеткие системы управления (НСУ).Одним из важнейших компонентов НСУ является база знаний, которая представляет собой совокупность нечетких правил «ЕСЛИ–ТО», определяющих взаимосвязь между входами и выходами исследуемой системы. Существуют различные типы нечетких правил: лингвистическая, реляционная, модель Такаги-Сугено и др.
Для многих приложений, связанных с управлением процессами, необходимо построение модели рассматриваемого процесса. Знание модели позволяет подобрать соответствующий регулятор (модуль управления). Однако часто построение корректной модели представляет собой трудную проблему, требующую иногда введения различных упрощений. Применение теории нечетких множеств для управления процессами не предполагает знания моделей этих процессов. Следует только сформулировать правила поведения в форме нечетких условных суждений типа «ЕСЛИ-ТО».

Рисунок 2.1 -. Структура нечеткой системы управления
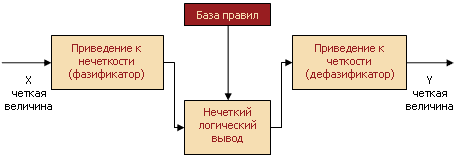
Процесс управления системой напрямую связан с выходной переменной нечеткой системы управления, но результат нечеткого логического вывода является нечетким, а физическое исполнительное устройство не способно воспринять такую команду. Необходимы специальные математические методы, позволяющие переходить от нечетких значений величин к вполне определенным. В целом весь процесс нечеткого управления можно разбить на несколько стадий: фаззификация, разработка нечетких правил и дефаззификация.
Фаззификаия подразумевает переход к нечеткости. На данной стадии точные значения входных переменных преобразуются в значения лингвистических переменных посредством применения некоторых положений теории нечетких множеств, а именно ‒ при помощи определенных функций принадлежности.
В нечеткой логике значения любой величины представляются не числами, а словами естественного языка и называются «термами». Так, значением лингвистической переменной «Дистанция» являются термы «Далеко», «Близко» и т. д. Для реализации лингвистической переменной необходимо определить точные физические значения ее термов. Допустим переменная «Дистанция» может принимать любое значение из диапазона от 0 до 60 метров. Согласно положениям теории нечетких множеств, каждому значению расстояния из диапазона в 60 метров может быть поставлено в соответствие некоторое число, от нуля до единицы, которое определяет степень принадлежностиданного физического значения расстояния (допустим, 10 метров) к тому или иному терму лингвистической переменной «Дистанция». Тогда расстоянию в 50 метров можно задать степень принадлежности к терму «Далеко», равную 0,85, а к терму «Близко» ‒ 0,15. Задаваясь вопросом, сколько всего термов в переменной необходимо для достаточно точного представления физической величины принято считать, что достаточно 3-7 термов на каждую переменнуюдля большинства приложений. Большинствоприменений вполне исчерпывается использованием минимального количества термов.Такое определение содержит два экстремальных значения (минимальное и максимальное) и среднее. Что касается максимального количества термов, то оно не ограничено и зависит целиком от приложения и требуемой точности описания системы. Число 7 же обусловлено емкостью кратковременной памяти человека, в которой, по современным представлениям, может храниться до семи единиц информации.
Принадлежность каждого точного значения к одному из термов лингвистической переменной определяется посредством функции принадлежности. Ее вид может быть абсолютно произвольным, однако сформировалось понятие о так называемых стандартных функциях принадлежности

Рисунок 2.2 ‒ Стандартные функции принадлежности
Стандартные функции принадлежности легко применимы к решению большинства задач. Однако если предстоит решать специфическую задачу, можно выбрать и более подходящую форму функции принадлежности, при этом можно добиться лучших результатов работы системы, чем при использовании функций стандартного вида.
Следующей стадией является стадия разработки нечетких правил.
На ней определяются продукционные правила, связывающие лингвистические переменные. Большинство нечетких систем используют продукционные правила для описания зависимостей между лингвистическими переменными. Типичное продукционное правило состоит из антецедента (частьЕСЛИ …) и консеквента (часть ТО…). Антецедент может содержать более одной посылки. В этом случае они объединяются посредством логических связок«И» или «ИЛИ».
Процесс вычисления нечеткого правила называется нечетким логическим выводом и подразделяется на два этапа: обобщение и заключение.
Пусть имеется следующее правило:
ЕСЛИ «Дистанция» = средняя И «Угол» =малый, ТО «Мощность» = средняя.
На первом шаге логического вывода необходимо определить степень принадлежности всего антецедента правила. Для этого в нечеткой логике существуют два оператора: Min(…) и Max(…). Первый вычисляет минимальное значение степени принадлежности, а второй ‒ максимальное значение. Когда применять тот или иной оператор, зависит от того, какой связкой соединены посылки в правиле. Если использована связка «И», применяется оператор Min(…). Если же посылки объединены связкой «Или», необходимо применить оператор Max(…). Ну а если в правиле всего одна посылка, операторы вовсе не нужны.
Следующим шагом является собственно вывод или заключение. Подобным же образом посредством операторов Min/Maxвычисляется значение консеквента. Исходными данными служат вычисленные на предыдущем шаге значения степеней принадлежности антецедентов правил.
После выполнения всех шагов нечеткого вывода мы находим нечеткое значение управляющей переменной. Чтобы исполнительное устройство смогло отработать полученную команду, необходим этап управления, на котором мы избавляемся от нечеткости и который называется дефаззификацией.
На этапе дефаззификации осуществляется переход от нечетких значений величин к определенным физическим параметрам, которые могут служить командами исполнительному устройству.
Результат нечеткого вывода, конечно же, будет нечетким. Например, если речь идет об управлении механизмом и команда для электромотора будет представлена термом «Средняя» (мощность), то для исполнительного устройства это ровно ничего не значит. В теории нечетких множеств процедура дефаззификации аналогична нахождению характеристик положения (математического ожидания, моды, медианы) случайных величин в теории вероятности. Простейшим способом выполнения процедуры дефаззификации является выбор четкого числа, соответствующего максимуму функции принадлежности. Однако пригодность этого способа ограничивается лишь одно экстремальными функциями принадлежности. Для устранения нечеткости окончательного результата существует несколько методов: метод центра максимума, метод наибольшего значения, метод центроида и другие. Для многоэкстремальных функций принадлежности наиболее часто используется дефаззификация путем нахождения центра тяжести плоской фигуры, ограниченной осями координат и функцией принадлежности.
2.3. Модели нечеткого логического вывода
Нечеткий логический вывод - это аппроксимация зависимости «входы–выход» на основе лингвистических высказываний типа «ЕСЛИ–ТО» и операций над нечеткими множествами. Нечеткая модель содержит следующие блоки:
‒
фаззификатор, преобразующий фиксированный
вектор влияющих факторов Xв вектор
нечетких множеств
 ,
необходимых для выполнения нечеткого
логического вывода;
,
необходимых для выполнения нечеткого
логического вывода;
‒ нечеткая
база знаний, содержащая информацию о
зависимости
 в виде лингвистических правил типа
«ЕСЛИ–ТО»;
в виде лингвистических правил типа
«ЕСЛИ–ТО»;
‒ машина
нечеткого логического вывода, которая
на основе правил базы знаний определяет
значение выходной переменной в виде
нечеткого множества ,
соответствующего нечетким значениям
входных переменных
,
соответствующего нечетким значениям
входных переменных ;
;
‒
дефаззификатор, преобразующий выходное
нечеткое множество
 в четкое число Y.
в четкое число Y.

Рисунок 2.3 ‒ Структура нечеткой модели.
2.3.1Нечеткая модель типа Мамдани
Данный алгоритм описывает несколько последовательно выполняющихся этапов. При этом каждый последующий этап получает на вход значения полученные на предыдущем шаге.

Рисунок 2.4 – Диаграмма деятельности процесса нечеткого вывода
Алгоритм примечателен тем, что он работает по принципу «черного ящика». На вход поступают количественные значения, на выходе они же. На промежуточных этапах используется аппарат нечеткой логики и теория нечетких множеств. В этом и состоит элегантность использования нечетких систем. Можно манипулировать привычными числовыми данными, но при этом использовать гибкие возможности, которые предоставляют системы нечеткого вывода.
В модели типа Мамдани взаимосвязь между входами X = (x 1 , x 2 ,…, x n)и выходом y определяется нечеткой базой знаний следующего формата:
 ,
,
где
 -
лингвистический терм, которым оценивается
переменная x i в строке с номером
-
лингвистический терм, которым оценивается
переменная x i в строке с номером ;
; ),
где
),
где -
количество строк-конъюнкций, в которых
выход
-
количество строк-конъюнкций, в которых
выход оценивается
лингвистическим термом
оценивается
лингвистическим термом ;
; -
количество термов, используемых для
лингвистической оценки выходной
переменной
-
количество термов, используемых для
лингвистической оценки выходной
переменной .
.
С помощью операций ∪(ИЛИ) и ∩ (И) нечеткую базу знаний можно переписать в более компактном виде:
 (1)
(1)
Все лингвистические термы в базе знаний (1) представляются как нечеткие множества, заданные соответствующими функциями принадлежности.
Нечеткая база знаний (1) может трактоваться как некоторое разбиение пространства влияющих факторов на подобласти с размытыми границами, в каждой из которых функция отклика принимает значение, заданное соответствующим нечетким множеством. Правило в базе знаний представляет собой «информационный сгусток», отражающий одну из особенностей зависимости «входы–выход». Такие «сгустки насыщенной информации» или «гранулы знаний» могут рассматриваться как аналог вербального кодирования, которое, как установили психологи, происходит в человеческом мозге при обучении. Видимо поэтому формирование нечеткой базы знаний в конкретной предметной области, как правило, не составляет трудностей для эксперта.
Введем следующие обозначения:
 -
функция принадлежности входа
-
функция принадлежности входа нечеткому терму
нечеткому терму ,
, т.е
т.е
 -
функция принадлежности выхода y нечеткому
терму
-
функция принадлежности выхода y нечеткому
терму ,
т.е.
,
т.е.
Степень
принадлежности входного вектора
 нечетким термам
нечетким термам из базы знаний (1) определяется
следующей системой нечетких логических
уравнений:
из базы знаний (1) определяется
следующей системой нечетких логических
уравнений:
Наиболее часто используются следующие реализации: для операции ИЛИ - нахождение максимума, для операции И- нахождение минимума.
Нечеткое множество , соответствующее входному вектору X * , определяется следующим образом:

где imp- импликация, обычно реализуемая как операция нахождения минимума; agg- агрегирование нечетких множеств, которое наиболее часто реализуется операцией нахождения максимума.
Четкое
значение выхода
 ,
соответствующее входному вектору
,
соответствующее входному вектору ,
определяется в результате дефаззификации
нечеткого множества
,
определяется в результате дефаззификации
нечеткого множества .
Наиболее часто применяется дефаззификация
по методу центра тяжести:
.
Наиболее часто применяется дефаззификация
по методу центра тяжести:

Модели типа Мамдани и типа Сугэно будут идентичными, когда заключения правил заданы четкими числами, т. е. в случае, если:
1) термы d j выходной переменной в модели типа Мамдани задаются синглтонами - нечеткими аналогами четких чисел. В этом случае степени принадлежностей для всех элементов универсального множества равны нулю, за исключением одного со степенью принадлежности равной единице;
2) заключения правил в базе знаний модели типа Сугэно заданы функциями, в которых все коэффициенты при входных переменных равны нулю.
2.3.2 Нечеткая модель типа Сугэно
На сегодняшний день существует несколько моделей нечеткого управления, одной из которых является модель Такаги-Сугено.
Модель Такаги-Сугено иногда носит называние Takagi-Sugeno-Kang. Причина состоит в том, что этот тип нечеткой модели был первоначально предложен Takagi и Sugeno. Однако Канг и Сугено провели превосходную работу над идентификацией нечеткой модели. Отсюда и происхождение названия модели.
В
модели типа Сугэно взаимосвязь между
входами  и
выходом y задается
нечеткой базой знаний вида:
и
выходом y задается
нечеткой базой знаний вида:
где
 -
некоторые числа.
-
некоторые числа.
База
знаний (3) аналогична (1) за исключением
заключений правил  ,
которые задаются не нечеткими термами,
а линейной функцией от входов:
,
которые задаются не нечеткими термами,
а линейной функцией от входов:
 ,
,
Таким
образом, база знаний в модели типа Сугэно
является гибридной - ее правила содержат
посылки в виде нечетких множеств и
заключения в виде четкой линейной
функции. База знаний (3) может трактоваться
как некоторое разбиение пространства
влияющих факторов на нечеткие подобласти,
в каждой из которых значение функции
отклика рассчитывается как линейная
комбинация входов. Правила являются
своего рода переключателями с одного
линейного закона «входы–выход» на
другой, тоже линейный. Границы подобластей
размытые, следовательно, одновременно
могут выполняться несколько линейных
законов, но с различными весами.
Результирующее значение выхода
 определяется
как суперпозиция линейных зависимостей,
выполняемых в данной точке
определяется
как суперпозиция линейных зависимостей,
выполняемых в данной точке  n-мерного факторного
пространства. Это может быть
взвешенное среднее
n-мерного факторного
пространства. Это может быть
взвешенное среднее
 ,
,
или взвешенная сумма
 .
.
Значения
 рассчитываются
как и для модели типа Мамдани, т. е. по
формуле (2).Обратим внимание, что в модели
Сугэно в качестве операций ˄ и ˅обычно
используются соответственно вероятностное
ИЛИ и
умножение. В этом случае нечеткая модель
типа Сугэно может рассматриваться как
особый класс многослойных нейронных
сетей прямого распространения сигнала,
структура которой изоморфна базе знаний.
Такие сети получили название
нейро-нечетких.
рассчитываются
как и для модели типа Мамдани, т. е. по
формуле (2).Обратим внимание, что в модели
Сугэно в качестве операций ˄ и ˅обычно
используются соответственно вероятностное
ИЛИ и
умножение. В этом случае нечеткая модель
типа Сугэно может рассматриваться как
особый класс многослойных нейронных
сетей прямого распространения сигнала,
структура которой изоморфна базе знаний.
Такие сети получили название
нейро-нечетких.
Математическая теория нечетких множеств (fuzzy sets) и нечеткая логика (fuzzy logic) являются обобщениями классической теории множеств и классической формальной логики. Данные понятия были впервые предложены американским ученым Лотфи Заде (Lotfi Zadeh) в 1965 г. Основной причиной появления новой теории стало наличие нечетких и приближенных рассуждений при описании человеком процессов, систем, объектов.
Прежде чем нечеткий подход к моделированию сложных систем получил признание во всем мире, прошло не одно десятилетие с момента зарождения теории нечетких множеств. И на этом пути развития нечетких систем принято выделять три периода.
Первый период (конец 60-х–начало 70 гг.) характеризуется развитием теоретического аппарата нечетких множеств (Л. Заде, Э. Мамдани, Беллман). Во втором периоде (70–80-е годы) появляются первые практические результаты в области нечеткого управления сложными техническими системами (парогенератор с нечетким управлением). Одновременно стало уделяться внимание вопросам построения экспертных систем, построенных на нечеткой логике, разработке нечетких контроллеров. Нечеткие экспертные системы для поддержки принятия решений находят широкое применение в медицине и экономике. Наконец, в третьем периоде, который длится с конца 80-х годов и продолжается в настоящее время, появляются пакеты программ для построения нечетких экспертных систем, а области применения нечеткой логики заметно расширяются. Она применяется в автомобильной, аэрокосмической и транспортной промышленности, в области изделий бытовой техники, в сфере финансов, анализа и принятия управленческих решений и многих других.
Триумфальное шествие нечеткой логики по миру началось после доказательства в конце 80-х Бартоломеем Коско знаменитой теоремы FAT (Fuzzy Approximation Theorem). В бизнесе и финансах нечеткая логика получила признание после того как в 1988 году экспертная система на основе нечетких правил для прогнозирования финансовых индикаторов единственная предсказала биржевой крах. И количество успешных фаззи-применений в настоящее время исчисляется тысячами.
Математический аппарат
Характеристикой нечеткого множества выступает функция принадлежности (Membership Function). Обозначим через MF c (x) – степень принадлежности к нечеткому множеству C, представляющей собой обобщение понятия характеристической функции обычного множества. Тогда нечетким множеством С называется множество упорядоченных пар вида C={MF c (x)/x}, MF c (x) . Значение MF c (x)=0 означает отсутствие принадлежности к множеству, 1 – полную принадлежность.
Проиллюстрируем это на простом примере. Формализуем неточное определение "горячий чай". В качестве x (область рассуждений) будет выступать шкала температуры в градусах Цельсия. Очевидно, что она будет изменяется от 0 до 100 градусов. Нечеткое множество для понятия "горячий чай" может выглядеть следующим образом:
C={0/0; 0/10; 0/20; 0,15/30; 0,30/40; 0,60/50; 0,80/60; 0,90/70; 1/80; 1/90; 1/100}.
Так, чай с температурой 60 С принадлежит к множеству "Горячий" со степенью принадлежности 0,80. Для одного человека чай при температуре 60 С может оказаться горячим, для другого – не слишком горячим. Именно в этом и проявляется нечеткость задания соответствующего множества.
Для нечетких множеств, как и для обычных, определены основные логические операции. Самыми основными, необходимыми для расчетов, являются пересечение и объединение.
Пересечение двух нечетких множеств (нечеткое "И"): A B: MF AB (x)=min(MF A (x), MF B (x)).
Объединение двух нечетких множеств (нечеткое "ИЛИ"): A B: MF AB (x)=max(MF A (x), MF B (x)).
В теории нечетких множеств разработан общий подход к выполнению операторов пересечения, объединения и дополнения, реализованный в так называемых треугольных нормах и конормах. Приведенные выше реализации операций пересечения и объединения – наиболее распространенные случаи t-нормы и t-конормы.
Для описания нечетких множеств вводятся понятия нечеткой и лингвистической переменных.
Нечеткая переменная описывается набором (N,X,A), где N – это название переменной, X – универсальное множество (область рассуждений), A – нечеткое множество на X.
Значениями лингвистической переменной могут быть нечеткие переменные, т.е. лингвистическая переменная находится на более высоком уровне, чем нечеткая переменная. Каждая лингвистическая переменная состоит из:
- названия;
- множества своих значений, которое также называется базовым терм-множеством T. Элементы базового терм-множества представляют собой названия нечетких переменных;
- универсального множества X;
- синтаксического правила G, по которому генерируются новые термы с применением слов естественного или формального языка;
- семантического правила P, которое каждому значению лингвистической переменной ставит в соответствие нечеткое подмножество множества X.
Рассмотрим такое нечеткое понятие как "Цена акции". Это и есть название лингвистической переменной. Сформируем для нее базовое терм-множество, которое будет состоять из трех нечетких переменных: "Низкая", "Умеренная", "Высокая" и зададим область рассуждений в виде X= (единиц). Последнее, что осталось сделать – построить функции принадлежности для каждого лингвистического терма из базового терм-множества T.
Существует свыше десятка типовых форм кривых для задания функций принадлежности. Наибольшее распространение получили: треугольная, трапецеидальная и гауссова функции принадлежности.
Треугольная функция принадлежности определяется тройкой чисел (a,b,c), и ее значение в точке x вычисляется согласно выражению:
$$MF\,(x) = \,\begin{cases} \;1\,-\,\frac{b\,-\,x}{b\,-\,a},\,a\leq \,x\leq \,b &\ \\ 1\,-\,\frac{x\,-\,b}{c\,-\,b},\,b\leq \,x\leq \,c &\ \\ 0, \;x\,\not \in\,(a;\,c)\ \end{cases}$$
При (b-a)=(c-b) имеем случай симметричной треугольной функции принадлежности, которая может быть однозначно задана двумя параметрами из тройки (a,b,c).
Аналогично для задания трапецеидальной функции принадлежности необходима четверка чисел (a,b,c,d):
$$MF\,(x)\,=\, \begin{cases} \;1\,-\,\frac{b\,-\,x}{b\,-\,a},\,a\leq \,x\leq \,b & \\ 1,\,b\leq \,x\leq \,c & \\ 1\,-\,\frac{x\,-\,c}{d\,-\,c},\,c\leq \,x\leq \,d &\\ 0, x\,\not \in\,(a;\,d) \ \end{cases}$$
При (b-a)=(d-c) трапецеидальная функция принадлежности принимает симметричный вид.
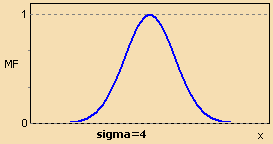
Функция принадлежности гауссова типа описывается формулой
$$MF\,(x) = \exp\biggl[ -\,{\Bigl(\frac{x\,-\,c}{\sigma}\Bigr)}^2\biggr]$$
и оперирует двумя параметрами. Параметр c обозначает центр нечеткого множества, а параметр отвечает за крутизну функции.
Совокупность функций принадлежности для каждого терма из базового терм-множества T обычно изображаются вместе на одном графике. На рисунке 3 приведен пример описанной выше лингвистической переменной "Цена акции", на рисунке 4 – формализация неточного понятия "Возраст человека". Так, для человека 48 лет степень принадлежности к множеству "Молодой" равна 0, "Средний" – 0,47, "Выше среднего" – 0,20.


Количество термов в лингвистической переменной редко превышает 7.
Нечеткий логический вывод
Основой для проведения операции нечеткого логического вывода является база правил, содержащая нечеткие высказывания в форме "Если-то" и функции принадлежности для соответствующих лингвистических термов. При этом должны соблюдаться следующие условия:
- Существует хотя бы одно правило для каждого лингвистического терма выходной переменной.
- Для любого терма входной переменной имеется хотя бы одно правило, в котором этот терм используется в качестве предпосылки (левая часть правила).
В противном случае имеет место неполная база нечетких правил.
Пусть в базе правил имеется m правил вида:
R 1: ЕСЛИ x 1 это A 11 … И … x n это A 1n , ТО y это B 1
…
R i: ЕСЛИ x 1 это A i1 … И … x n это A in , ТО y это B i
…
R m: ЕСЛИ x 1 это A i1 … И … x n это A mn , ТО y это B m ,
где x k , k=1..n – входные переменные; y – выходная переменная; A ik – заданные нечеткие множества с функциями принадлежности.
Результатом нечеткого вывода является четкое значение переменной y * на основе заданных четких значений x k , k=1..n.
В общем случае механизм логического вывода включает четыре этапа: введение нечеткости (фазификация), нечеткий вывод, композиция и приведение к четкости, или дефазификация (см. рисунок 5).
Алгоритмы нечеткого вывода различаются главным образом видом используемых правил, логических операций и разновидностью метода дефазификации. Разработаны модели нечеткого вывода Мамдани, Сугено, Ларсена, Цукамото.
Рассмотрим подробнее нечеткий вывод на примере механизма Мамдани (Mamdani). Это наиболее распространенный способ логического вывода в нечетких системах. В нем используется минимаксная композиция нечетких множеств. Данный механизм включает в себя следующую последовательность действий.
- Процедура фазификации: определяются степени истинности, т.е. значения функций принадлежности для левых частей каждого правила (предпосылок). Для базы правил с m правилами обозначим степени истинности как A ik (x k), i=1..m, k=1..n.
Нечеткий вывод. Сначала определяются уровни "отсечения" для левой части каждого из правил:
$$alfa_i\,=\,\min_i \,(A_{ik}\,(x_k))$$
$$B_i^*(y)= \min_i \,(alfa_i,\,B_i\,(y))$$
Композиция, или объединение полученных усеченных функций, для чего используется максимальная композиция нечетких множеств:
$$MF\,(y)= \max_i \,(B_i^*\,(y))$$
где MF(y) – функция принадлежности итогового нечеткого множества.
Дефазификация, или приведение к четкости. Существует несколько методов дефазификации. Например, метод среднего центра, или центроидный метод:
$$MF\,(y)= \max_i \,(B_i^*\,(y))$$
Геометрический смысл такого значения – центр тяжести для кривой MF(y). Рисунок 6 графически показывает процесс нечеткого вывода по Мамдани для двух входных переменных и двух нечетких правил R1 и R2.

Интеграция с интеллектуальными парадигмами
Гибридизация методов интеллектуальной обработки информации – девиз, под которым прошли 90-е годы у западных и американских исследователей. В результате объединения нескольких технологий искусственного интеллекта появился специальный термин – "мягкие вычисления" (soft computing), который ввел Л. Заде в 1994 году. В настоящее время мягкие вычисления объединяют такие области как: нечеткая логика, искусственные нейронные сети, вероятностные рассуждения и эволюционные алгоритмы. Они дополняют друг друга и используются в различных комбинациях для создания гибридных интеллектуальных систем.
Влияние нечеткой логики оказалось, пожалуй, самым обширным. Подобно тому, как нечеткие множества расширили рамки классической математическую теорию множеств, нечеткая логика "вторглась" практически в большинство методов Data Mining, наделив их новой функциональностью. Ниже приводятся наиболее интересные примеры таких объединений.
Нечеткие нейронные сети
Нечеткие нейронные сети (fuzzy-neural networks) осуществляют выводы на основе аппарата нечеткой логики, однако параметры функций принадлежности настраиваются с использованием алгоритмов обучения НС. Поэтому для подбора параметров таких сетей применим метод обратного распространения ошибки, изначально предложенный для обучения многослойного персептрона. Для этого модуль нечеткого управления представляется в форме многослойной сети. Нечеткая нейронная сеть как правило состоит из четырех слоев: слоя фазификации входных переменных, слоя агрегирования значений активации условия, слоя агрегирования нечетких правил и выходного слоя.
Наибольшее распространение в настоящее время получили архитектуры нечеткой НС вида ANFIS и TSK. Доказано, что такие сети являются универсальными аппроксиматорами.
Быстрые алгоритмы обучения и интерпретируемость накопленных знаний – эти факторы сделали сегодня нечеткие нейронные сети одним из самых перспективных и эффективных инструментов мягких вычислений.
Адаптивные нечеткие системы
Классические нечеткие системы обладают тем недостатком, что для формулирования правил и функций принадлежности необходимо привлекать экспертов той или иной предметной области, что не всегда удается обеспечить. Адаптивные нечеткие системы (adaptive fuzzy systems) решают эту проблему. В таких системах подбор параметров нечеткой системы производится в процессе обучения на экспериментальных данных. Алгоритмы обучения адаптивных нечетких систем относительно трудоемки и сложны по сравнению с алгоритмами обучения нейронных сетей, и, как правило, состоят из двух стадий: 1. Генерация лингвистических правил; 2. Корректировка функций принадлежности. Первая задача относится к задаче переборного типа, вторая – к оптимизации в непрерывных пространствах. При этом возникает определенное противоречие: для генерации нечетких правил необходимы функции принадлежности, а для проведения нечеткого вывода – правила. Кроме того, при автоматической генерации нечетких правил необходимо обеспечить их полноту и непротиворечивость.
Значительная часть методов обучения нечетких систем использует генетические алгоритмы. В англоязычной литературе этому соответствует специальный термин – Genetic Fuzzy Systems.
Значительный вклад в развитие теории и практики нечетких систем с эволюционной адаптацией внесла группа испанских исследователей во главе с Ф. Херрера (F. Herrera).
Нечеткие запросы
Нечеткие запросы к базам данных (fuzzy queries) – перспективное направление в современных системах обработки информации. Данный инструмент дает возможность формулировать запросы на естественном языке, например: "Вывести список недорогих предложений о съеме жилья близко к центру города", что невозможно при использовании стандартного механизма запросов. Для этой цели разработана нечеткая реляционная алгебра и специальные расширения языков SQL для нечетких запросов. Большая часть исследований в этой области принадлежит западноевропейским ученым Д. Дюбуа и Г. Праде.
Нечеткие ассоциативные правила
Нечеткие ассоциативные правила (fuzzy associative rules) – инструмент для извлечения из баз данных закономерностей, которые формулируются в виде лингвистических высказываний. Здесь введены специальные понятия нечеткой транзакции, поддержки и достоверности нечеткого ассоциативного правила.
Нечеткие когнитивные карты
Нечеткие когнитивные карты (fuzzy cognitive maps) были предложены Б. Коско в 1986 г. и используются для моделирования причинных взаимосвязей, выявленных между концептами некоторой области. В отличие от простых когнитивных карт, нечеткие когнитивные карты представляют собой нечеткий ориентированный граф, узлы которого являются нечеткими множествами. Направленные ребра графа не только отражают причинно-следственные связи между концептами, но и определяют степень влияния (вес) связываемых концептов. Активное использование нечетких когнитивных карт в качестве средства моделирования систем обусловлено возможностью наглядного представления анализируемой системы и легкостью интерпретации причинно-следственных связей между концептами. Основные проблемы связаны с процессом построения когнитивной карты, который не поддается формализации. Кроме того, необходимо доказать, что построенная когнитивная карта адекватна реальной моделируемой системе. Для решения данных проблем разработаны алгоритмы автоматического построения когнитивных карт на основе выборки данных.
Нечеткая кластеризация
Нечеткие методы кластеризации, в отличие от четких методов (например, нейронные сети Кохонена), позволяют одному и тому же объекту принадлежать одновременно нескольким кластерам, но с различной степенью. Нечеткая кластеризация во многих ситуациях более "естественна", чем четкая, например, для объектов, расположенных на границе кластеров. Наиболее распространены: алгоритм нечеткой самоорганизации c-means и его обобщение в виде алгоритма Густафсона-Кесселя.
Литература
- Заде Л. Понятие лингвистической переменной и его применение к принятию приближенных решений. – М.: Мир, 1976.
- Круглов В.В., Дли М.И. Интеллектуальные информационные системы: компьютерная поддержка систем нечеткой логики и нечеткого вывода. – М.: Физматлит, 2002.
- Леоленков А.В. Нечеткое моделирование в среде MATLAB и fuzzyTECH. – СПб., 2003.
- Рутковская Д., Пилиньский М., Рутковский Л. Нейронные сети, генетические алгоритмы и нечеткие системы. – М., 2004.
- Масалович А. Нечеткая логика в бизнесе и финансах. www.tora-centre.ru/library/fuzzy/fuzzy-.htm
- Kosko B. Fuzzy systems as universal approximators // IEEE Transactions on Computers, vol. 43, No. 11, November 1994. – P. 1329-1333.
- Cordon O., Herrera F., A General study on genetic fuzzy systems // Genetic Algorithms in engineering and computer science, 1995. – P. 33-57.
Математическая теория нечетких множеств (fuzzy sets) инечеткая логика (fuzzy logic ) являются обобщениями классическойтеории множеств и классической формальной логики. Данные понятия были впервые предложены американским ученым Лотфи Заде (Lotfi Zadeh) в 1965 г. Основной причиной появления новой теории стало наличие нечетких иприближенных рассуждений при описании человеком процессов, систем, объектов.
Одной из основных характеристик нечеткой логики является лингвистическая переменная, которая определяется набором вербальных (словесных) характеристик некоторого свойства. Рассмотрим лингвистическую переменную «скорость», которую можно характеризовать через набор следующих понятий-значений: «малая», «средняя» и «большая», данные значения называются термами.
Следующей основополагающей характеристикой нечеткой логики является понятие функции принадлежности. Функция принадлежности определяет, насколько мы уверены в том, что данное значение лингвистической переменной (например, скорость) можно отнести к соответствующим ей категориям (в частности для лингвистической переменной скорость к категориям «малая», «средняя», «большая»).
На следующем рисунке (первая часть) отражено, как одни и те же значения лингвистической переменной могут соответствовать различным понятиям-значениям или термам. Тогда функции принадлежности, характеризующие нечеткие множества понятий скорости, можно выразить графически, в более привычном математическом виде (рис. 35, вторая часть).

Из рисунка видно, что степень, с которой численное значение скорости, например v = 53, совместимо с понятием «большая», есть 0,7, в то время как совместимость значений скорости, равных 48 и 45, с тем же понятием есть 0,5 и 0,1 соответственно.
Существует свыше десятка типовых форм кривых для задания функций принадлежности. Наибольшее распространение получили: треугольная, трапецеидальная и гауссова функции принадлежности.
Треугольная функция принадлежности определяется тройкой чисел (a,b,c), и ее значение в точке x вычисляется согласно выражению:

При (b-a)=(c-b) имеем случай симметричной треугольной функции принадлежности, которая может быть однозначно задана двумя параметрами из тройки (a,b,c).
Аналогично для задания трапецеидальной функции принадлежности необходима четверка чисел (a,b,c,d):

При (b-a)=(d-c) трапецеидальная функция принадлежности принимает симметричный вид.
 Рисунок
1. Типовые кусочно-линейные
функции
принадлежности.
Рисунок
1. Типовые кусочно-линейные
функции
принадлежности.
Функция принадлежности гауссова типа описывается формулой
![]()
и оперирует двумя параметрами. Параметр c обозначает центр нечеткого множества, а параметр отвечает за крутизну функции.
 Рисунок
2. Гауссова функция принадлежности.
Рисунок
2. Гауссова функция принадлежности.
Совокупность функций принадлежности для каждого терма из базового терм-множества T обычно изображаются вместе на одном графике. На рисунке приведен пример описанной лингвистической переменной "Цена акции".
 Рис.
Описание лингвистической переменной
"Цена акции".
Рис.
Описание лингвистической переменной
"Цена акции".
Количество термов в лингвистической переменной редко превышает 7.
Основой для проведения операции нечеткого логического вывода является база правил, содержащая нечеткие высказывания в форме "Если-то" и функции принадлежности для соответствующих лингвистических термов. При этом должны соблюдаться следующие условия:
Существует хотя бы одно правило для каждого лингвистического терма выходной переменной .
Для любого терма входной переменной имеется хотя бы одно правило, в котором этот терм используется в качестве предпосылки (левая часть правила).
В противном случае имеет место неполная база нечетких правил.
Пусть в базе правил имеется m правил вида: R 1: ЕСЛИ x 1 это A 11 … И … x n это A 1n , ТО y это B 1 … R i: ЕСЛИ x 1 это A i1 … И … x n это A in , ТО y это B i … R m: ЕСЛИ x 1 это A i1 … И … x n это A mn , ТО y это B m , где x k , k=1..n – входные переменные; y – выходная переменная; A ik – термы соответствующих переменных с функциями принадлежности.
Результатом нечеткого вывода является четкое значение переменной y * на основе заданных четких значений x k , k=1..n.
В общем случае механизм логического вывода включает четыре этапа: введение нечеткости (фазификация), нечеткий вывод, композиция и приведение к четкости, или дефазификация (см. рисунок 5).
 Рисунок
5. Система нечеткого логического вывода.
Рисунок
5. Система нечеткого логического вывода.
Алгоритмы нечеткого вывода различаются главным образом видом используемых правил, логических операций и разновидностью метода дефазификации. Разработаны модели нечеткого вывода Мамдани, Сугено, Ларсена, Цукамото.
Рассмотрим подробнее нечеткий вывод на примере механизма Мамдани (Mamdani). Это наиболее распространенный способ логического вывода в нечетких системах. В нем используется минимаксная композиция нечетких множеств. Данный механизм включает в себя следующую последовательность действий.
Процедура фазификации: определяются степени истинности, т.е. значения функций принадлежности для левых частей каждого правила (предпосылок). Для базы правил с m правилами обозначим степени истинности как A ik (x k), i=1..m, k=1..n.
Нечеткий вывод. Сначала определяются уровни "отсечения" для левой части каждого из правил:
![]()
Композиция, или объединение полученных усеченных функций, для чего используется максимальная композиция нечетких множеств:
![]()
где MF(y) – функция принадлежности итогового нечеткого множества.
4. Дефазификация, или приведение к четкости. Под дефаззификацией понимается процедура преобразования нечетких величин, получаемых в результате нечеткого вывода, в четкие. Эта процедура является необходимой в тех случаях, где требуется интерпретация нечетких выводов конкретными четкими величинами, т.е. когда на основе функции принадлежности возникает потребность определить для каждой точки вZ числовые значения.
В настоящее время отсутствует систематическая процедура выбора стратегии дефаззификации. На практике часто используют два наиболее общих метода: метод центра тяжести (ЦТ - центроидный), метод максимума (ММ).
Для дискретных пространств в центроидном методе формула для вычисления четкого значения выходной переменной представляется в следующем виде:
Стратегия дефаззификации ММ предусматривает подсчет всех тех z , чьи функции принадлежности достигли максимального значения. В этом случае (для дискретного варианта) получим
где z - выходная переменная, для которой функция принадлежности достигла максимума;m - число таких величин.
Из этих двух наиболее часто используемых стратегий дефаззификации, стратегия ММ дает лучшие результаты для переходного режима, аЦТ - в установившемся режиме из-за меньшей среднеквадратической ошибки.
Пример нечеткого правила

Как работает.
По максимальному значению функций принадлежности (для скорости 60 км в час значение функции принадлежности «низкая» = 0, а для дорожных условий 75 % от нормы значение функции принадлежности «тяжелые» = около 0.7) по 0.7 проводится прямая которая рассекает геометрическую фигуру заключения (подача топлива) на две части, в результате берется фигура лежащая ниже прямой а верхняя часть отбрасывается. Это для одного правила, таких правил может быть 100 и более в реальных задачах.
Рассмотрим процесс получения нечеткого вывода по трем правилам одновременно с последующим получением четкого решения. Данная процедура включает в себя три этапа. На первом этапе получают нечеткие выводы по каждому из правил в отдельности по схеме, показанной на рис. 3.13. На втором этапе производится сложение результирующих функций, полученных на предыдущем этапе (применяется логическая операция ИЛИ, т.е. берется максимум). Третий этап - этап получения четкого решения (дефаззификация). Здесь применяется любой из известных классических методов: метод центра тяжести и т.д. Полученное в виде числового значения четкое решение служит задающей величиной системы управления. В нашем примере это будет величина, в соответствии с которой ИСУ должна будет изменить подачу топлива. Процесс получения нечетких выводов по нескольким правилам с последующей дефаззификацией для рассматриваемого примера показан на рис. 3.14. При начальном значении скорости = 65 км в час, и дорожным условиям = 80 % от норматива получаем следующую схему решения об уровне подачи топлива.

Рис. 3.14. Процесс получения нечетких выводов по правилам и их преобразование в четкое решение.
Как видно из рис. 3.14, в результате дефаззификации получено четкое решение: при заданных значениях скорости и дорожных условий подача топлива должна составлять 63% от
максимального значения. Таким образом, несмотря на нечеткость выводов, в итоге получено вполне четкое и определенное решение. Такое решение, вероятно, принял бы и водитель автомобиля в процессе движения. Данный пример демонстрирует великолепные возможности моделирования человеческих рассуждений на основе методов теории нечетких множеств.



