Часто при выборке данных бывает необходимо объединить информацию из нескольких связанных таблиц. Сделать это можно посредством вложенных запросов, либо при помощи соединения с помощью SQL.
Вложенные запросы
В рамках нашего примера, допустим, что нам понадобилось узнать имена узлов, которые посещали сайт www.dom2.ru. Требуемую информацию можно получить запросом:
SELECT hst_name FROM hosts WHERE hst_pcode IN (SELECT vis_hstcode FROM visits, sites WHERE (sit_pcode = vis_sitcode) AND (sit_name LIKE "www.dom2.ru"));
Рассмотрим этот запрос более пристально. Первый оператор SELECT нужен для выборки имен узлов. Чтобы выбрать требуемые нам имена, в запросе указана секция WHERE, в которой первичный ключ таблицы «Узлы» (hst_pcode) проверяется на принадлежность множеству (оператор IN). Судя по всему, множество для проверки на принадлежность должен вернуть второй оператор SELECT, находящийся в скобках. Рассмотрим его отдельно:
SELECT vis_hstcode FROM visits, sites WHERE (sit_pcode = vis_sitcode) AND (sit_name LIKE "www.dom2.ru")
Для содержимого таблиц в нашем примере, вложенный запрос вернет следующее множество значений
Соединение с помощью SQL
Как и говорилось выше, одним из способов выборки данных из нескольких таблиц является соединение таблиц с помощью SQL. Основная цель такого соединения - создание нового отношения, которое будет содержать данные из двух или более исходных отношений.
Внутреннее соединение
Рассмотрим пример:
SELECT hst_name, sit_name, vis_timestamp FROM hosts, visits, sites WHERE (hst_pcode = vis_hstcode) AND (vis_sitcode = sit_pcode)
Данный запрос вернет следующие данные
| hst_name | sit_name | vis_timestamp |
| ws1 | www.dom2.ru | 2012-08-01 07:59:58.209028 |
| ws1 | www.vkontakte.ru | 2012-08-01 08:00:10.315083 |
| 1-1 | www.vkontakte.ru | 2012-08-01 08:00:20.025087 |
| 1-2 | www.opennet.ru | 2012-08-01 08:00:26.260159 |
В этом примере из трех таблиц (hosts, visits, sites) выбирается по одному полю и создается новая таблица, в которой будут собраны имена узлов, посещаемых сайтов и время посещений. Представление соединяемых данных регламентируется условиями в операторе WHERE. Видно, что имеется два условия, которые соединяют три таблицы. Поскольку в таблице посещений (visits) вместо имени узла и наименования сайта указаны их идентификаторы, при соединении таблиц мы добавляем условие, чтобы связать по идентификаторам данные и тогда все встанет на свои места. Если по каким-то причинам, вопреки ссылочной целостности в таблице посещений будут находиться записи с идентификатором несуществующего узла или сайта, они не появятся в результирующем наборе данных запроса в этом примере.
Указанный выше пример немного упрощен и из-за немного упрощения теряется наглядность. Более наглядная форма запроса, соединяющего несколько таблиц и возвращающего тот же самый набор данных будет иметь вид
SELECT hst_name, sit_name, vis_timestamp FROM hosts JOIN visits ON (hst_pcode = vis_hstcode) JOIN sites ON (vis_sitcode = sit_pcode);
В запросе присутствует два оператора JOIN… ON. Поскольку «Join» можно перевести как «соединение» или «объединение», этот пример более красноречив. Если попытаться перевести текст SQL-запроса на русский, получится что-то вроде
ВЫБРАТЬ (поля) hst_name, sit_name, vis_timestamp ИЗ (таблицы) hosts СОЕДИНИВ (с таблицей) visits ПО (условию) (hst_pcode = vis_hstcode) СОЕДИНИВ (с таблицей) sites ПО (условию) (vis_sitcode = sit_pcode);
Русские слова в круглых скобках добавлены для облегчения понимания работы запроса. Вы можете использовать любой из вышеперечисленных способов написания запросов.
Использованные выше способы соединения таблиц называются внутреннее соединение (inner join). У такого способа соединения есть недостатки. Например, если у нас не было посещений на один из сайтов, либо один из узлов не совершил ни одного посещения, то в результирующем наборе данных сайт или узел будут отсутствовать. В примере выше видно, что сайт www.yandex.ru отсутствует в данных, равно как и узел 1-3.Иногда это нежелательно и в таких случаях используют внешнее соединение (outer join). Внешнее соединение может быть левым (left join) и правым (right join). Сторона соединения (левая или правая) соответствует таблице, данные из которой будут выбираться полностью. Таким образом, при использовании LEFT JOIN, данные из таблицы слева от оператора JOIN будут выбираться полностью. Закрепим это примером. Допустим, надо выбрать ВСЕ узлы и связанные с ними посещения. Сделать это можно посредством запроса
SELECT hst_name, vis_timestamp FROM hosts LEFT JOIN visits ON (hst_pcode = vis_hstcode);
Обратите внимание на данные, которые вернутся в ответ на запрос
| hst_name | vis_timestamp |
| ws1 | 2012-08-01 07:59:58.209028 |
| ws1 | 2012-08-01 08:00:10.315083 |
| 1-1 | 2012-08-01 08:00:20.025087 |
| 1-2 | 2012-08-01 08:00:26.260159 |
| 1-3 |
Видно, что узлу 1-3 не соответствует ни одно посещение, но он все равно в списке. Аналогичным образом работает RIGHT JOIN. Запрос, который вернет тот же набор данных можно записать с использованием RIGHT JOIN:
SELECT hst_name, vis_timestamp FROM visits RIGHT JOIN hosts ON (hst_pcode = vis_hstcode);
В этом случае, надо сменить LEFT JOIN на RIGHT JOIN и поменять местами таблицы visits и hosts в запросе.
Использование UNION
Иногда бывает нужно получить два списка записей из таблиц в виде одного. Для этой цели может быть использовано ключевое слово UNION, которое позволяет объединить результирующие наборы данных двух запросов в один набор данных. Допустим, надо получить некоторый список, в котором были бы узлы сети и имена сайтов. Таблицы разные, соответственно и запросы будут разными. Как объединить все в один набор данных? Легко, но есть определенные требования к такому «склеиванию» запросов:
§ запросы должны содержать одинаковое число полей;
§ типы данных полей объединяемых запросов так же должны совпадать.
В остальном же, использование UNION не является сложным. Например, чтобы получить список имен узлов и имен сайтов в виде одного набора данных, выполним такой запрос:
SELECT hst_name AS name FROM hosts UNIONSELECT sit_name AS name FROM sites;
При таком подходе возможны проблемы с сортировкой записей. Чтобы список сайтов шел после списка узлов, можно умышленно добавить целочисленное поле, где указывать номер, который будет участвовать в сортировке. Например
SELECT 1 AS level, hst_name AS name FROM hosts UNIONSELECT 2 AS level, sit_name AS name FROM sitesORDER BY level, name;
Условия EXISTS и NOT EXISTS
Иногда бывает необходимо выбрать из таблицы записи, которым соответствуют (или не соответствуют) записи в других таблицах. Допустим, что нам нужен список сайтов, на которые не было посещений. Получить такой список можно запросом
SELECT sit_name FROM sites WHERE ((SELECT COUNT(*) FROM visits WHERE vis_sitcode = sit_pcode) = 0);
Для нашего примера, список будет коротким:
| sit_name |
| www.yandex.ru |
Запрос работает следующим образом:
§ из таблицы sites выбирается код сайта и его наименование;
§ код сайта передается во вложенный запрос, который считает записи с этим кодом в таблице visits;
§ функция COUNT(*) сосчитает записи и вернет их количество, который будет передано в условие;
§ при истинности условия (количество записей равно 0) имя сайта добавляется в список.
Если некоторым этот запрос покажется непонятным, то можно добиться тех же результатов посредством запроса с использованием NOT EXISTS:
SELECT sit_name FROM sites WHERE NOT EXISTS (SELECT vis_pcode FROM visits WHERE vis_sitcode = sit_pcode);
Выражение NOT EXISTS (на мой взгляд) вносит дополнительную ясность и более доступно для понимания. Аналогично работает выражение EXISTS, которое проверяет наличие записей.
Представления (VIEW)
Представления (VIEW) используются для обеспечения возможности сохранения сложного запроса на сервере под указанным именем. Допустим, вам часто приходится запрашивать данные, набирая объемный запрос. Если подойти к проблеме прогрессивно, то можно создать представление. Делается это несложно. Например,
CREATE VIEW show_dom2 ASSELECT hst_name FROM hosts WHERE hst_pcode IN (SELECT vis_hstcode FROM visits, sites WHERE (sit_pcode = vis_sitcode) AND (sit_name LIKE "www.dom2.ru"));
Собственно, всё. Внимательный наблюдатель, наверное, заметил, что по-сути, можно взять запрос и в самом начале добавить слова «CREATE VIEW <имя> AS». Именно по такому принципу можно рекомендовать создание представлений. Создайте запрос, убедитесь в его работоспособности и потом допишите все необходимое, чтобы сохранить этот запрос на сервере как представление. Единственный недостаток использования представлений заключается в том, что некоторые особо сложные приемы написания запросов могут не работать в представлениях. К сожалению, в документации по postgreSQL очень мало сведений о представлениях и однозначно узнать, что можно использовать, а что нет вы сможете методом проб и ошибок. Сохранив запрос на сервере как представление, вы сможете выполнить его сколько угодно раз, запросом типа
SELECT * FROM show_dom2;
Важно отметить, что при выполнении запроса, который выбирает данные из представления - данные выбираются из таблиц посредством запроса, который хранится в представлении. Представление является полностью динамическим и данные, возвращаемые представлением будут актуальными при обновлении данных в таблицах. Удалить представление можно запросом типа
DROP VIEW show_dom2;
Заключение
данные отчет запрос заказ
В данной курсовой работе была разработана база данных "Склад канцтоваров", содержащая всю необходимую информацию о товарах, покупателях, поставщиках и заказах. С помощью моей базы можно без затруднений и специальных знаний вести базу данных, которая позволяет делать все операции с клиентами, заказами, производителями. То есть добавлять, изменять, обновлять, удалять и просматривать все имеющиеся и вводимые данные. На основе базы данных были составлены запросы и отчеты.
ЗАКЛЮЧЕНИЕ
СПИСОК ЛИТЕРАТУРЫ
ПРИЛОЖЕНИЕ А
ПРИЛОЖЕНИЕ Б
SQL позволяет вкладывать запросы друг в друга. Обычно подзапрос возвращает одно значение, которое проверяется на предмет истинности предиката.
Виды условий поиска:
. Сравнение с результатом вложенного запроса (=, >=)
. Проверка на принадлежность результатам подзапроса (IN)
. Проверка на существование (EXISTS)
. Многократное (количественное) сравнение (ANY, ALL)
Примечания по вложенным запросам:
. Подзапрос должен выбирать только один столбец (за исключением подзапроса с предикатом EXISTS), и тип данных его результата должен соответствовать типу данных значения, указанному в предикате.
. В ряде случаев можно использовать ключевое слово DISTINCT для гарантии получения единственного значения.
. Во вложенном запросе нельзя включать раздел ORDER BY и UNION.
. Подзапрос может находиться и лева и справа от условия поиска.
. В подзапросах могут использоваться функции агрегирования без раздела GROUP BY, которые автоматически выдают специальное значение для любого количества строк, специальный предикат IN, а также выражения, основанные на столбцах.
. По возможности следует вместо подзапросов использовать соединение таблиц JOIN.
Примеры на вложенные запросы :
SELECT * FROM Orders WHERE SNum=(SELECT SNum FROM SalesPeople WHERE SName=’Motika’)
SELECT * FROM Orders WHERE SNum IN (SELECT SNum FROM SalesPeople WHERE City=’London’)
SELECT * FROM Orders WHERE SNum=(SELECT DISTINCT SNum FROM Orders WHERE CNum=2001)
SELECT * FROM Orders WHERE Amt>(SELECT AVG(Amt) FROM Orders WHERE Odate=10/04/1990)
SELECT * FROM Customer WHERE CNum=(SELECT SNum+1000 FROM SalesPeople WHERE SName=’Serres’)
2) Связанные подзапросы
В SQL можно создавать подзапросы со ссылкой на таблицу из внешнего запроса. В этом случае подзапрос выполняется многократно, по одному разу для каждой строки таблицы из внешнего запроса. Поэтому важно, чтобы подзапрос использовал индекс. Подзапрос может обращаться к той же таблице, чтоб и внешний. Если внешний запрос возвращает относительно небольшое число строк, то связанный подзапрос будет работать быстрее несвязанного. Если подзапрос возвращает небольшое число строк, то связанный запрос выполнится медленнее несвязанного.
Примеры на связанные подзапросы:
SELECT * FROM SalesPeople Main WHERE 1(SELECT AVG(Amt) FROM Orders O2 WHERE O2.CNum=O1.CNum) //возвращает все заказы, величина которых превосходит среднюю величины заказа для данного покупателя
3) Предикат EXISTS
Синтаксическая форма: EXISTS ()
Предикат использует подзапрос в качестве аргумента и оценивает его как истинный, если в подзапросе есть выходные данные, а в противном случае как ложный. Выполняется подзапрос один раз и может содержать несколько столбцов, поскольку их значения не проверяются, а просто фиксируется результат наличия строк.
Примечания по предикату EXISTS:
. EXISTS – предикат, возвращающий значение TRUE или FALSE, и его можно применять отдельно или вместе с другими булевыми выражениями.
. EXISTS не может использовать функции агрегирования в своем подзапросе.
. В коррелирующих (связанных, зависимых – Correlated) подзапросах предикат EXISTS выполняется для каждой строки внешней таблицы.
. Можно комбинировать предикат EXISTS с соединениями таблиц.
Примеры на предикат EXISTS:
SELECT * FROM Customer WHERE EXISTS(SELECT * FROM Customer WHERE City=’San Jose’) – возвращает всех покупателей, если кто-то из них проживает в San Jose.
SELECT DISTINCT SNum FROM Customer First WHERE NOT EXISTS (SELECT * FROM Customer Send WHERE Send.SNum=First.SNum AND Send.CNumFirst.CNum) – возвращает номера продавцов, обслуживших только одного покупателя.
SELECT DISTINCT F.SNum, SName, F.City FROM SalesPeople F, Customer S WHERE EXISTS (SELECT * FROM Customer T WHERE S.SNum=T.SNum AND S.CNumT.CNum AND F.SNum=S.SNum) – возвращает номера, имена и города проживания всех продавцов, обслуживших нескольких покупателей.
SELECT * FROM SalesPeople Frst WHERE EXISTS (SELECT * FROM Customer Send WHERE Frst.SNum=Send.SNum AND 1
4) Предикаты количественного сравнения
Синтаксическая форма: {=|>|=|} ANY|ALL ()
Эти предикаты используют в качестве аргумента подзапрос, однако, по сравнению с предикатом EXISTS, они применяются в конъюнкции с предикатами отношения (=,>=). В этом смысле они сходны с предикатом IN, но применяются только с подзапросами. Стандарт допускает использовать вместо ANY ключевое слово SOME, однако не все СУБД его поддерживают.
Примечания по предикатам сравнения:
. Предикат ALL принимает значение TRUE, если каждое значение, выбранное в процессе выполнения подзапроса, удовлетворяет условию, заданному в предикате внешнего запроса. Чаще всего он используется с неравенствами.
. Предикат ANY принимает значение TRUE, если хотя бы одно значение, выбранное в процессе выполнения подзапроса, удовлетворяет условию, заданному в предикате внешнего запроса. Чаще всего он используется с неравенствами.
. Если подзапрос не возвращает строк, то ALL автоматически принимает значение TRUE (считается, что условие сравнения выполняется), а для ANY – FALSE.
. Если сравнение не имеет значения TRUE ни для одной строки и есть одна или несколько строк с NULL значением, то ANY возвращает UNKNOWN.
. Если сравнение не имеет значения FALSE ни для одной строки и есть одна или несколько строк с NULL значением, то ALL возвращает UNKNOWN.
Примеры на предикат количественного сравнения:
SELECT * FROM SalesPeople WHERE City=ANY(SELECT City FROM Customer)
SELECT * FROM Orders WHERE Amt ALL(SELECT Rating FROM Customer WHERE City=’Rome’)
5) Предикат уникальности
UNIQUE|DISTINCT ()
Предикат служит для проверка уникальности (отсутствия дублей) в выходных данных подзапроса. Причем в предикате UNIQUT строки с NULL значениями считаются уникальными, а в предикате DISTINCT два неопределенных значения считаются равными друг другу.
6) Предикат совпадений
MATCH ()
Предикат MATCH проверяет, будет ли значение строки запроса совпадать со значением любой строки, полученной в результате подзапроса. От предикатов IN И ANY такой подзапрос отличается тем, что позволяет обрабатывать «частичные» (PARTIAL) совпадения, которые могут встречаться среди строк, имеющих часть NULL-значений.
7) Запросы в разделе FROM
Фактически допустимо использовать подзапрос везде, где допускается ссылка на таблицу.
SELECT CName, Tot_Amt FROM Customer, (SELECT CNum, SUM(Amt) AS Tot_Amt FROM Orders GROUP BY CNum) WHERE City=’London’ AND Customer.CNum=Orders.CNum
//подзапрос возвращает суммарную величину заказов, сделанных каждым покупателем из Лондона.
8) Рекурсивные запросы
WITH RECURSIVE
Q1 AS SELECT … FROM … WHERE …
Q2 AS SELECT … FROM … WHERE …
В прошлом уроке мы столкнулись с одним неудобством. Когда мы хотели узнать, кто создал тему "велосипеды", и делали соответствующий запрос:
Вместо имени автора, мы получали его идентификатор. Это и понятно, ведь мы делали запрос к одной таблице - Темы, а имена авторов тем хранятся в другой таблице - Пользователи. Поэтому, узнав идентификатор автора темы, нам надо сделать еще один запрос - к таблице Пользователи, чтобы узнать его имя:

В SQL предусмотрена возможность объединять такие запросы в один путем превращения одного из них в подзапрос (вложенный запрос). Итак, чтобы узнать, кто создал тему "велосипеды", мы сделаем следующий запрос:
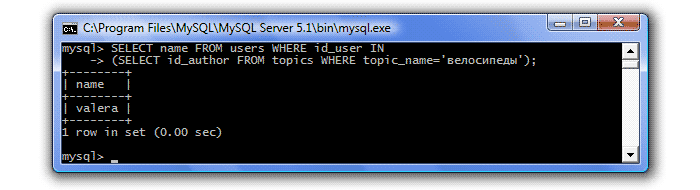
То есть, после ключевого слова WHERE , в условие мы записываем еще один запрос. MySQL сначала обрабатывает подзапрос, возвращает id_author=2, и это значение передается в предложение WHERE внешнего запроса.
В одном запросе может быть несколько подзапросов, синтаксис у такого запроса следующий: Обратите внимание, что подзапросы могут выбирать только один столбец, значения которого они будут возвращать внешнему запросу. Попытка выбрать несколько столбцов приведет к ошибке.
Давайте для закрепления составим еще один запрос, узнаем, какие сообщения на форуме оставлял автор темы "велосипеды":

Теперь усложним задачу, узнаем, в каких темах оставлял сообщения автор темы "велосипеды":

Давайте разберемся, как это работает.
- Сначала MySQL выполнит самый глубокий запрос:
- Полученный результат (id_author=2) передаст во внешний запрос, который примет вид:
- Полученный результат (id_topic:4,1) передаст во внешний запрос, который примет вид:
- И выдаст окончательный результат (topic_name: о рыбалке, о рыбалке). Т.е. автор темы "велосипеды" оставлял сообщения в теме "О рыбалке", созданной Сергеем (id=1) и в теме "О рыбалке", созданной Светой (id=4).
- Не рекомендуется создавать запросы со степенью вложения больше трех. Это приводит к увеличению времени выполнения и к сложности восприятия кода.
- Приведенный синтаксис вложенных запросов, скорее наиболее употребительный, но вовсе не единственный. Например,
мы могли бы вместо запроса
написать
Т.е. мы можем использовать любые операторы, используемые с ключевым словом WHERE (их мы изучали в прошлом уроке).
Подзапрос - это запрос, содержащийся в выражении ключевого слова WHERE другого запроса с целью дополнительных ограничений на выводимые данные. Подзапросы называют также вложенными запросами. Их используют для наложения условий на выводимые данные. Подзапросы могут использоваться с операторами SELECT, INSERT, UPDATE или DELETE.
В некоторых случаях подзапрос можно использовать вместо связывания таблиц, тем самым связывая данные таблиц неявно. При использовании в запросе подзапроса сначала выполняется подзапрос, а только потом - содержащий его запрос, причем с учетом условий выполнения подзапроса. Подзапрос можно использовать либо в выражении ключевого слова WHERE, либо в выражении ключевого слова HAVING главного запроса. Логические операции и операции сравнения типа =, >, <, о, IN, NOT IN, AND, OR и т п. можно использовать в подзапросе. Все, что применимо к обычному запросу, применимо и к подзапросу.
При составлении подзапросов необходимо придерживаться следующих правил.
Подзапрос необходимо заключить в круглые скобки.
Подзапрос может ссылаться только на один столбец в выражении своего ключевого слова SELECT, за исключением случаев, когда в главном запросе используется сравнение с несколькими столбцами из подзапроса.
Ключевое слово ORDER BY использовать в подзапросе нельзя, хотя в главном запросе ORDER BY использоваться может. Вместо ORDER BY в подзапросе можно использовать GROUP BY.
Подзапрос, возвращающий несколько строк данных, можно использовать только в операторах, допускающих множество значений, например в IN.
Операцию BETWEEN по отношению к подзапросу использовать нельзя, но ее можно использовать в самом подзапросе. Базовый синтаксис оператора с подзапросом выглядит следующим образом.
SELECT имя_столбиа FROM таблица WHERE имя_столбца = (SELECT имя__столбца FROM таблица WHERE условия);
Точно так же, как подзапрос можно вложить в главный запрос, подзапрос можно вложить и в подзапрос. В главном запросе подзапрос выполняется до выполнения главного, точно так же и в подзапросе вложенный в него подзапрос будет выполнен первым
Пример. Пусть требуется определить количество предметов обучения с оценкой, превышающей среднее значение оценки студента с идентификатором 301:
SELECT COUNT (DISTINCT subj_id), mark FROM exam_marks GROUP BY mark HAVING mark > (SELECT AVG(mark) FROM exam_marks WHERE stud_id=301);
При использовании в операторе нескольких подзапросов увеличивается время, необходимое для обработки запроса, и повышается вероятность ошибок из-за усложнения оператора.
Связанные подзапросы допускаются во многих реализациях SQL. При использовании подзапросов во внутреннем запросе можно ссылаться на таблицу, имя которой указано в предложении FROM внешнего запроса. Такие подзапросы называются связанными. Связанный подзапрос выполняется по одному разу для каждой строки таблицы основного запроса, а именно:
Выбирается строка из таблицы, имя которой указано во внешнем запросе;
Выполняется подзапрос, и полученное в результате его выполнения значение применяется для анализа этой строки в условии WHERE внешнего запроса;
По результату оценки этого условия принимается решение о включении / невключении строки в состав выходных данных;
Процедура повторяется для следующей строки таблицы внешнего запроса.
Предложение GROUP BY позволяет группировать выводимые SELECT–запросом записи по значению некоторого поля. Использование предложения HAVING позволяет при выводе осуществлять фильтрацию таких групп. Предикат предложения HAVING оценивается не для каждой строки результата, а для каждой группы выходных записей, сформированной предложением GROUP BY внешнего запроса.
SELECT exam_date, SUM(mark) FROM exam_marks a GROUP BY exam_date
HAVING 10< (SELECT COUNT(mark) FROM exam_marks b
WHERE a.exam_date=b.exam_date);
Необходимо по данным таблицы exam_marks определить сумму полученных студентами оценок (значений поля mark), сгруппировав значения оценок по датам экзаменов и исключив те дни, когда число студентов, сдававших в течении дня экзамены, было меньше десяти.
Резюме: подзапрос представляет собой запрос, выполняемый в рамках другого запроса для задания дополнительных условий на выводимые данные. Подзапрос можно использовать в выражениях ключевых слов WHERE и HAVING. Синтаксис подзапросов практически не отличается от синтаксиса обычного запроса, имеются лишь небольшие ограничения. Одним из таких ограничений является запрет на использование в подзапросах ключевого слова ORDER BY, однако, вместо него можно использовать GROUP BY, чем достигается практически тот же эффект. Подзапросы используются для размещения в запросах условий, точные данные для которых не известны, тем самым расширяя возможности и гибкость SQL.
В лекции обсуждаются вопросы построения и применения подзапросов при извлечении и изменении данных.Подзапросы
Язык SQL разрешает использовать в других операторах языка DML подзапросы , которые являются внутренними запросами, определяемыми оператором SELECT .
Подзапрос - очень мощное средство языка SQL. Он позволяет строить сложные иерархии запросов, многократно выполняемые в процессе построения результирующего набора или выполнения одного из операторов изменения данных (DELETE , INSERT , UPDATE ).
Условно подзапросы иногда подразделяют на три типа, каждый из которых является сужением предыдущего:
- табличный подзапрос , возвращающий набор строк и столбцов;
- подзапрос строки , возвращающий только одну строку, но, возможно, несколько столбцов (такие подзапросы часто используются во встроенном SQL);
- скалярный подзапрос , возвращающий значение одного столбца в одной строке.
Подзапрос позволяет решать следующие задачи:
- определять набор строк, добавляемый в таблицу на одно выполнение оператора INSERT ;
- определять данные, включаемые в представление, создаваемое оператором CREATE VIEW ;
- определять значения, модифицируемые оператором UPDATE ;
- указывать одно или несколько значений во фразах WHERE и HAVING оператора SELECT ;
- определять во фразе FROM таблицу как результат выполнения подзапроса ;
- применять коррелированные подзапросы . Подзапрос называется коррелированным, если запрос, содержащийся в предикате, имеет ссылку на значение из таблицы (внешней к данному запросу), которая проверяется посредством данного предиката.
Hекоторые СУБД (например, СУБД Oracle) позволяют на основе подзапроса создавать новые таблицы с помощью оператора CREATE TABLE .
Простым примером использования подзапроса может служить следующий оператор:
В данном операторе подзапрос всегда должен возвращать единственное значение, которое будет проверяться в предикате. Если подзапрос вернет более одного значения, то СУБД выдаст сообщение об ошибке выполнения SQL-оператора.
В случае если подзапрос не выберет ни одной строки, то предикат будет равен UNKNOWN , что большинством СУБД интерпретируется как FALSE .
Стандарт определяет запись предиката в форме "значение оператор подзапрос ". Однако некоторые СУБД также позволяют записывать предикат в форме, указывающей подзапрос слева от оператора сравнения.
Например:
Очень часто с подзапросами используются агрегирующие функции, предоставляющие возможность сформулировать условие типа "больше, чем среднее по группе".
Например:
Если результатом подзапроса становится группа строк (это случается всегда, когда условие не гарантирует уникальности значения проверяемого предикатом внутреннего запроса), то следует использовать оператор IN , осуществляющий выбор одного значения из указываемого множества.
Например:
В этом случае предикат принимает значение TRUE , если хотя бы одно из значений, возвращаемых подзапросом , удовлетворяет условию.
Однако применение оператора IN имеет и некоторые смысловые недостатки: в запросе четко не определяется, сколько строк должны быть результатом выполнения запроса. При построении отношений для реальной модели данных это может приводить к некоторой неоднозначности и зависимости от самих данных. В противном случае, если модель данных предполагает в качестве постоянного результата подзапроса наличие только одной строки и, соответственно, использует оператор сравнения = , а структура данных позволяет ввод значений, когда в результате подзапроса будет более одной строки, то при использовании такого SQL-оператора в какой-то момент времени может проявиться ошибка.
Если в запросе участвуют более двух таблиц, то для большей наглядности имена полей иногда квалифицируют именами таблиц, указывая их через точку. Стандарт позволяет не квалифицировать имя поля именем таблицы в том случае, если не возникает неоднозначности (поле сначала ищется в таблице, указанной фразой FROM текущего запроса, затем внешнего запроса и т.д.).
Очень часто вместо записи оператора SELECT с использованием подзапроса можно применять соединения. Однако на практике большинство СУБД подзапросы выполняют более эффективно. Тем не менее, при проектировании комплекса программ с критичными требованиями по быстродействию, разработчик должен проанализировать план выполнения SQL-оператора для конкретной СУБД.
Наиболее продвинутые СУБД, такие как Oracle, предоставляют ряд SQL-операторов, позволяющих оценить производительность выполнения конкретного оператора языка SQL, а также определить уровень оптимизации, применяемый для данного оператора.
Подзапрос может быть указан как в предикате, определяемом фразой WHERE , так и в предикате по группам, определяемом фразой HAVING .
Например:
Коррелированные подзапросы
В операторе SELECT из внутреннего подзапроса можно ссылаться на столбцы внешнего запроса, указанного во фразе SELECT . Такой подзапрос выполняется для каждой строки таблицы, определяя условие ее вхождения в формируемый результирующий набор.
Например:
В данном случае для каждой строки таблицы tbl1 будет проверяться условие, что значение поля f2 совпадает со значением строки таблицы tbl2 , где значение поля f3 равно значению поля f3 внешней таблицы (tbl1 ). Это простейший пример коррелированного подзапроса .
Очень часто требуется, чтобы подзапрос использовал те же данные, что и внешняя таблица. В этом случае обязательно применение алиасов.
Например:
В случае коррелированного подзапроса во фразе HAVING можно использовать только агрегирующие функции, так как каждый раз на момент выполнения подзапроса в качестве проверяемой строки, к значениям которой имеет доступ подзапрос , выступает результат группирования строк на основе агрегирующих функций основного запроса.
Например:
Построение предиката для подзапроса, возвращающего несколько строк
Если в предикате надо сравнить значение с некоторым множеством, то, как было показано выше, можно использовать оператор IN .
Для того чтобы проверить, существуют ли строки, удовлетворяющие конкретному условию подзапроса , применяется оператор EXISTS .
Например:
Этот запрос будет формировать не пустой результирующий набор только в том случае, если в какое-либо значение столбца f4 таблицы была занесена дата, например: "10/11/2003".
Преимущество применения оператора EXISTS с результатами подзапроса состоит в том, что подзапрос может возвращать как множество строк, так и множество столбцов.
При коррелированном подзапросе оператор EXISTS будет вычисляться каждый раз для каждой строки внешнего запроса.
В стандарте SQL-92 не предусмотрено использование в подзапросах , к которым применяется оператор EXISTS агрегирующих функций. Однако некоторые СУБД позволяют такой вид подзапросов .
Для использования результата подзапроса в предикате также применяются операторы ANY и ALL , которые были подробно рассмотрены в предыдущих лекциях.
Приведем пример использования оператора ANY :
Данный оператор определяет, что в результирующий набор будут включены все строки, значение столбца f3 которых присутствует в таблице tbl2 .
Применение подзапросов в операторах изменения данных
К операторам языка DML, кроме оператора SELECT , относятся операторы, позволяющие изменять данные в таблицах. Это оператор INSERT , выполняющий добавление одной или нескольких строк в таблицу, оператор DELETE , удаляющий из таблицы одну или несколько строк, и оператор UPDATE , изменяющий значения столбцов таблицы.
Оператор INSERT
Оператор INSERT
INSERT INTO table_name [ (field .,:) ] { VALUES (value .,:) } | subquery | {DEFAULT VALUES};
Оператор INSERT может добавлять в таблицу как одну, так и несколько строк. Список полей (field .,:) указывает имена полей и порядок занесения в них значений из списка значений, определяемого фразой VALUES , или как результат выполнения подзапроса .
Список, определяемый фразой VALUES , называется конструктором значений таблицы и указывается в круглых скобках через запятую.
Если список полей (field .,:) опущен, то порядок занесения значений будет соответствовать порядку столбцов, указанному в операторе CREATE TABLE при создании данной таблицы.
Если для столбцов, на которые установлено ограничение NOT NULL , не указано добавляемых данных, то СУБД инициирует ошибку выполнения SQL-оператора.
Следующий оператор INSERT демонстрирует копирование строк таблицы tbl2 , выполняемое на основе подзапроса :
INSERT INTO tbl1(f1,f2,f3) (SELECT f1,f2,f3 FROM tbl2);
Очевидно, что количество полей, указываемое списком полей, и типы данных этих полей должны совпадать с количеством полей и их типами данных в конструкторе значений таблицы или в результирующем наборе, формируемом подзапросом .
Оператор DELETE
Оператор DELETE в стандарте SQL-92 имеет следующее формальное описание:
Оператор DELETE используется для удаления из таблицы строк, указанных условием во фразе WHERE (поисковое удаление, searched deletion) или WHERE CURRENT OF (позиционное удаление, positioned deletion).
Позиционное удаление, определяемое фразой WHERE CURRENT OF , удаляя строки из курсора, соответственно удаляет их и из той таблицы базы данных, на базе которой был построен этот курсор.
Если оператор DELETE применяется к какому-либо представлению, то данные удаляются также из созданной на основе последнего таблицы базы данных.
Никогда нельзя забывать, что если фраза WHERE будет отсутствовать или предикат во фразе WHERE будет всегда принимать значение TRUE , то оператор DELETE удалит из таблицы все строки.
Оператор UPDATE
Оператор UPDATE в стандарте SQL-92 имеет следующее формальное описание:
Оператор UPDATE применяется для внесения изменений в данные таблиц.
Выражение expr , используемое для вычисления значения столбца, может быть как простым выражением, так и подзапросом , возвращающим единственное значение. В выражении можно ссылаться на старое значение изменяемого столбца и других столбцов текущей записи.
При вычислении значений столбцов можно применять условное выражение CASE и выражение CAST для приведения типов.
Например:
Условное выражение CASE
Условное выражение CASE позволяет выбрать одно из нескольких значений на основании указываемого условия.
Условное выражение CASE имеет следующее формальное описание:
{ CASE { expr WHEN expr THEN { expr | NULL }} | { WHEN expr THEN { expr | NULL }} [ ELSE { expr | NULL } ] END} | { NULLIF {expr1,expr2) } | {COALESCE (expr .,:) }
Условное выражение CASE может быть записано, соответственно, в четырех формах:
- CASE
с выражениями. Например:
SELECT f1, CASE f3 WHEN "abc" THEN "1_abc" END FROM tbl1;
- CASE
с предикатами. Например:
SELECT f1, CASE WHEN f3= "abc" THEN "1_abc" ELSE f3 END FROM tbl1;
- NULLIF - если выражения, указанные в скобках, не совпадают, то выбирается первое из этих значений, в противном случае устанавливается значение NULL . Например:
- COALESCE
- выбирается первое значение в списке, не равное NULL
. Например:
INSERT INTO tbl1(f1,f2) VALUES (1+ COALESCE(SELECT MAX(f1) FROM tbl1, 0), 100);
Для успешного выполнения оператора UPDATE требуется ряд условий, включающий следующие:
- наличие соответствующих привилегий;
- для представления требуется определение его как изменяемого;
- при изменении представлений применяются ограничения WITH CHECK OPTION или WITH CASCADED CHECK OPTION , установленные при создании этого представления;
- в транзакциях "только чтение" изменение доступно только для временных таблиц;
- выражения, используемые для определения значений, не могут содержать подзапросы с агрегирующими функциями;
- для обновляемого курсора, указанного фразой FOR UPDATE , каждый изменяемый столбец также должен быть определен как FOR UPDATE ;
- в курсоре с фразой ORDER BY нельзя выполнять изменение столбцов, указанных в этой фразе.



