Глава I. Теоретическая часть.................................................................... 4
1.1 Краткая история развития поисковых систем.................................... 4
1.4 Обзор основных мировых поисковых систем.................................... 7
1.4.1 Google................................................................................................ 7
1.4.2 Yahoo................................................................................................ 9
1.4.3 Baidu................................................................................................ 10
1.5 Обзор основных Российских поисковых систем.............................. 11
1.5.1 Yandex............................................................................................. 11
1.5.2 Rambler............................................................................................ 13
1.5.3 Апорт.............................................................................................. 13
1.5.4 Mail.ru............................................................................................. 15
Глава II. Обработка информации в маркетинговом исследовании....... 17
2.1 Текстовый процессор Microsoft Word.............................................. 17
2.2 Табличный редактор Excel............................................................... 17
2.3 Редактор Microsoft Power Point........................................................ 17
Глава III . Организация рабочего места оператора ЭВМ..................... 19
3.1 Общие требования безопасности...................................................... 19
3.2 Требования безопасности перед началом работы........................... 20
3.3 Требования безопасности во время работы..................................... 20
3.4 Требования безопасности в аварийных ситуациях.......................... 21
Заключение.............................................................................................. 22
Список литературы................................................................................. 23
Введение
Всемирная сеть очень важна и полезна практически для любого! Каждый пользователь Интернета может найти в нем массу разнообразной и интереснейшей информации, а также использовать все богатейшие возможности сети. Для меня решающими обстоятельствами в выборе темы «Обзор современных поисковых систем в интернете», для своей квалификационной работы, стала во-первых достаточная известность мне этой темы, в силу частого посещения мной всемирной сети, а также актуальность темы на сегодняшний день. Ресурсы Интернета давно перестали быть просто игрушкой, превратившись в незаменимый инструмент для повседневной работы людей многих профессий. Быстрый рост информации в сети сделали его океаном разнообразнейших данных, важность которых растет пропорционально их объему. По оценке экспертов объем информации, передаваемой по каналам Интернет, удваивается каждые полгода. Ежедневно в сети появляются миллионы новых документов, и естественно, что без систем поиска они в подавляющем своем большинстве остались бы не востребованными, вообще не были бы не кем найдены, и все то огромное количество информации оказалось бы никому не нужным. Возникла необходимость создания таких средств, которые позволили бы легко ориентироваться в информационных ресурсах глобальных сетей, быстро и надежно находить нужные сведения. В интернете появились специальные поисковые средства. Еще несколько лет назад бытовало такое мнение: в Интернете есть все, но найти там ничего невозможно. Однако с появлением и быстрым развитием поисковых каталогов, поисковых машин, и всевозможных поисковых программ ситуация изменилась, и теперь в Сети срочно понадобившуюся информацию иногда можно найти быстрее, чем в книге, лежащей на столе.
Наиболее популярным и используемым способом поиска в Интернете является использование поисковых систем. Что же такое поисковая система? Поисковая система – портал, осуществляющий поиск, сбор и сортировку информации в сети Интернет. Поисковые системы это инструмент, позволяющий пользователю глобальной сети в кратчайшие сроки найти интересующую его информацию.
Первоочередная задача любой поисковой системы – доставлять людям именно ту информацию, которую они ищут.
Получая результат, пользователь оценивает работу системы, руководствуясь несколькими основными параметрами. Нашел ли он то, что искал? Если не нашел, то сколько раз ему пришлось перефразировать запрос, чтобы найти искомое? Насколько актуальную информацию он смог найти? Насколько быстро обрабатывала запрос поисковая машина? Насколько удобно были представлены результаты поиска? Был ли искомый результат первым или же сотым? Как много ненужного мусора было найдено наравне с полезной информацией? Найдется ли нужная информация, при обращении к поисковой системе, скажем, через неделю, или через месяц?
Моя работа имеет следующую структуру:
1) Введение.
2) I глава – включает в себя краткую историю развития поисковых систем, основных поисковых систем, а также обзор основных мировых и российских поисковиков.
3) II глава – методы использования компьютерных программ и аппаратных средств для маркетинговых исследований.
4) III глава – включает в себя организацию рабочего места оператора ЭВМ и технику безопасности и охрану труда на рабочем месте.
5) Заключение – общие выводы по всей квалификационной работе, а так же точку зрения автора о том какими поисковиками лучше всего пользоваться.
6) Список литературы.
Глава I. Теоретическая часть 1.1 Краткая история развития поисковых систем
Одним из первых способов организации доступа к информационным ресурсам сети стало создание каталогов сайтов, в которых ссылки на ресурсы группировались согласно тематике. Первым таким проектом стал сайт Yahoo, открывшийся в апреле 1994 года. После того, как число сайтов в каталоге Yahoo значительно увеличилось, была добавлена возможность поиска информации по каталогу. Это, конечно же, не было поисковой системой в полном смысле, так как область поиска была ограничена только ресурсами, присутствующими в каталоге, а не всеми ресурсами сети Интернет.
Каталоги ссылок широко использовались ранее, но практически утратили свою популярность в настоящее время. Причина этого очень проста – даже современные каталоги, содержащие огромное количество ресурсов, представляют информацию лишь об очень малой части сети Интернет. Самый большой каталог сети DMOZ (или Open Directory Project) содержит информацию о 5 миллионах ресурсов, в то время как база поисковой системы Google состоит из более чем 8 миллиардов документов.
Первой полноценной поисковой системой стал проект WebCrawler появившийся в 1994 году.
В 1995 году появились поисковые системы Lycos и AltaVista. Последняя долгие годы была лидером в области поиска информации в Интернет.
В 1997 году Сергей Брин и Лари Пейдж создали Google самую популярную на сегодняшний момент поисковую систему в мире.
Реализованы как простая программная система, которая запрашивает информацию из удаленных участков Интернет, используя стандартные cетевые протоколы. 4. Наиболее популярные русскоязычные справочно-поисковые системы в интернет 4.1 Rambler Поисковая система Рамблер начала свое существование с 1996 года. На сегодняшний день она является одной из самых популярных в РуНете, уступая лишь...
Информационных ресурсов в определённой предметной области, поиск и выдачу сведений, необходимых для удовлетворения информационных потребностей установленного контингента пользователей – абонентов системы. 2.2 Особенности поисковых систем Особенности поисковых систем. В работе поисковый процесс представлен четырьмя стадиями: формулировка (происходит до начала поиска); действие (начинающийся...
Этих решений вполне разумно и верно. Пока Международная Организация по Стандартизации (Organization for International Standartization - ISO) тратила годы, создавая окончательный стандарт для компьютерных сетей, пользователи ждать не желали. Активисты Internet начали устанавливать IP-программное обеспечение на все возможные типы компьютеров. Вскоре это стало единственным приемлемым способом для...
Образовательные ресурсы www.spb. osi.ru/ic/distant Дистанционное обучение в Интернет www.examen.ru Экзамены и тесты www.kbsu.ru/~book/ Учебник информатики Mega. km.ru Энциклопедии и словари Поиск информации в Интернете: подводные камни Проблемы, не лежащие на поверхности, нередко дают о себе знать лишь "задним числом", после того как определенный этап поисковых работ завершен и, ...
Тематические коллекции ссылок - это списки, составленные группой профессионалов или даже коллекционерами-одиночками. Очень часто узкоспециализированная тема может быть раскрыта одним специалистом лучше, чем группой сотрудников крупного каталога. Тематических коллекций в Сети так много, что давать конкретные адреса не имеет смысла.
Подбор доменного имени
Каталог - удобная система поиска, однако для того, чтобы попасть на сервер компании Microsoft или IBM , вряд ли имеет смысл обращаться к каталогу. Угадать название соответствующего сайта нетрудно: www.microsoft.com , www.ibm.com или www.microsoft.ru , www.ibm.ru - сайты российских представительств этих компаний.
Аналогично, если пользователю необходим сайт , посвященный погоде в мире, его логично искать на сервере www.weather.com . В большинстве случаев поиск сайта с ключевым словом в названии эффективнее, чем поиск документа, в тексте которого это слово используется. Если западная коммерческая компания (или проект) имеет односложное название и реализует в Сети свой сервер , то его имя с высокой вероятностью укладывается в формат www.name.com , а для Рунета (российской части Сети) - www.name.ru , где name - имя компании или проекта. Подбор адреса может успешно конкурировать с другими приемами поиска, поскольку при подобной системе поиска можно установить соединение с сервером, который не зарегистрирован ни в одной поисковой системе. Однако, если подобрать искомое имя не удается, придется обратиться к поисковой машине.
Поисковые машины
Скажи мне, что ты ищешь в Интернете, и я скажу, кто ты
Если бы компьютер был высокоинтеллектуальной системой, которой можно было легко объяснить, что вы ищете, то он выдавал бы два-три документа - именно те, которые вам нужны. Но, к сожалению, это не так, и в ответ на запрос пользователь обычно получает длинный список документов, многие из которых не имеют никакого отношения к тому, о чем он спрашивал. Такие документы называются нерелевантными (от англ. relevant - подходящий, относящийся к делу). Таким образом, релевантный документ - это документ, содержащий искомую информацию. Очевидно, что от умения грамотно выдавать запрос зависит процент получаемых релевантных документов. Доля релевантных документов в списке всех найденных поисковой машиной документов называется точностью поиска. Нерелевантные документы называют шумовыми. Если все найденные документы релевантные (шумовых нет), то точность поиска составляет 100%. Если найдены все релевантные документы, то полнота поиска - 100%.
Таким образом, качество поиска определяется двумя взаимозависимыми параметрами: точностью и полнотой поиска. Увеличение полноты поиска снижает точность , и наоборот.
Как работает поисковая машина
Поисковые системы можно сравнить со справочной службой, агенты которой обходят предприятия, собирая информацию в базу данных (рис. 4.21). При обращении в службу информация выдается из этой базы. Данные в базе устаревают, поэтому агенты их периодически обновляют. Некоторые предприятия сами присылают данные о себе, и к ним агентам приезжать не приходится. Иными словами, справочная служба имеет две функции: создание и постоянное обновление данных в базе и поиск информации в базе по запросу клиента.
Рис.
4.21.
Аналогично, поисковая машина состоит из двух частей: так называемого робота (или паука), который обходит серверы Сети и формирует базу данных поискового механизма.
База робота в основном формируется им самим (робот сам находит ссылки на новые ресурсы) и в гораздо меньшей степени - владельцами ресурсов, которые регистрируют свои сайты в поисковой машине. Помимо робота (сетевого агента, паука, червяка), формирующего базу данных, существует программа , определяющая рейтинг найденных ссылок.
Принцип работы поисковой машины сводится к тому, что она опрашивает свой внутренний каталог (базу данных) по ключевым словам, которые пользователь указывает в поле запроса, и выдает список ссылок, ранжированный по релевантности .
Следует отметить, что, отрабатывая конкретный запрос пользователя, поисковая система оперирует именно внутренними ресурсами (а не пускается в путешествие по Сети, как часто полагают неискушенные пользователи), а внутренние ресурсы, естественно, ограниченны. Несмотря на то что база данных поисковой машины постоянно обновляется, поисковая машина не может проиндексировать все Web-документы: их число слишком велико. Поэтому всегда существует вероятность , что искомый ресурс просто неизвестен конкретной поисковой системе.
Эту мысль наглядно иллюстрирует рис. 4.22. Эллипс 1 ограничивает множество всех Web-документов, существующих на некоторый момент времени, эллипс 2 - все документы, которые проиндексированы данной поисковой машиной, а эллипс 3 - искомые документы. Таким образом, найти с помощью данной поисковой машины можно лишь ту часть искомых документов, которые ею проиндексированы.
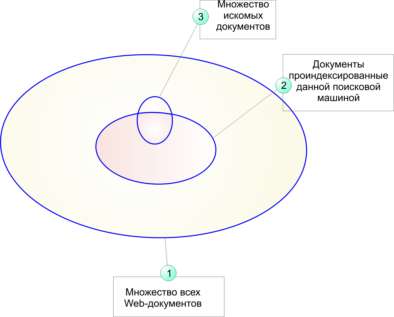
Рис. 4.22.
Проблема недостаточности полноты поиска состоит не только в ограниченности внутренних ресурсов поисковика, но и в том, что скорость робота ограниченна, а количество новых Web-документов постоянно растет. Увеличение внутренних ресурсов поисковой машины не может полностью решить проблему, поскольку скорость обхода ресурсов роботом конечна.
При этом считать, что поисковая машина содержит копию исходных ресурсов Интернета, было бы неправильно. Полная информация (исходные документы) хранится отнюдь не всегда, чаще хранится лишь ее часть - так называемый индексированный список , или индекс , который гораздо компактнее текста документов и позволяет быстрее отвечать на поисковые запросы.
Для построения индекса исходные данные преобразуются так, чтобы объем базы был минимальным, а поиск осуществлялся очень быстро и давал максимум полезной информации. Объясняя, что такое индексированный список , можно провести параллель с его бумажным аналогом - так называемым конкордансом, т.е. словарем, в котором в алфавитном порядке перечислены слова, употребляемые конкретным писателем, а также указаны ссылки на них и частота их употребления в его произведениях.
Очевидно, что конкорданс (словарь) гораздо компактнее исходных текстов произведений и найти в нем нужное слово намного проще, нежели перелистывать книгу в надежде наткнуться на нужное слово .
Построение индекса
Схема построения индекса показана на рис. 4.23. Сетевые агенты, или роботы-пауки, "ползают" по Сети, анализируют содержимое Web-страниц и собирают информацию о том, что и на какой странице было обнаружено.
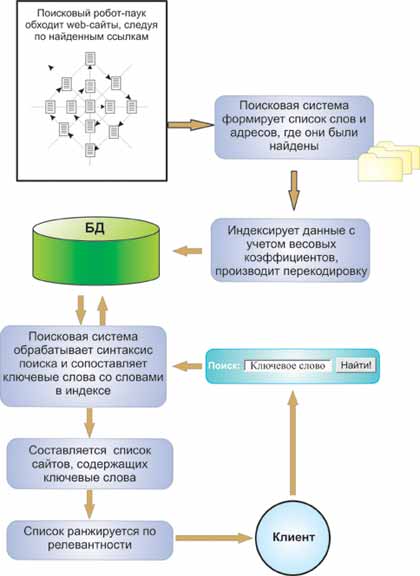
Рис. 4.23.
При нахождении очередной HTML-страницы большинство поисковых систем фиксируют слова, картинки, ссылки и другие элементы (в разных поисковых системах по-разному), содержащиеся на ней. Причем при отслеживании слов на странице фиксируется не только их наличие, но и местоположение, т.е. где эти слова находятся: в заголовке (title), подзаголовках ( subtitles ), в метатэгах 1Метатэги - это служебные тэги, позволяющие разработчикам помещать на Web-страницы служебную информацию, в том числе для того, чтобы сориентировать поисковую машину. ( meta tags ) или в других местах. При этом обычно фиксируются значимые слова, а союзы и междометия типа "а", "но" и "или" игнорируются. Метатэги позволяют владельцам страниц определить ключевые слова и тематику, по которым индексируется страница. Это может быть актуально в случае, когда ключевые слова имеют несколько значений. Метатэги могут сориентировать поисковую систему при выборе из нескольких значений слова на единственно правильное. Однако метатэги работают надежно только в том случае, когда заполняются честными владельцами сайта. Недобросовестные владельцы Web-сайтов помещают в свои метатэги наиболее популярные в Сети слова, не имеющие ничего общего с темой сайта. В результате посетители попадают на незапрашиваемые сайты, повышая тем самым их рейтинг. Именно поэтому многие современные поисковики либо игнорируют метатэги, либо считают их дополнительными по отношению к тексту страницы. Каждый робот поддерживает свой список ресурсов, наказанных за недобросовестную рекламу.
Очевидно, что если вы ищете сайты по ключевому слову "собака", то поисковый механизм должен найти не просто все страницы, где упоминается слово "собака", а те, где это слово имеет отношение к теме сайта. Для того чтобы определить, в какой степени то или иное слово имеет отношение к профилю некоторой Web-страницы, необходимо оценить, насколько часто оно встречается на странице, есть ли по данному слову ссылки на другие страницы или нет. Короче говоря, необходимо ранжировать найденные на странице слова по степени важности. Словам присваиваются весовые коэффициенты в зависимости от того, сколько раз и где они встречаются (в заголовке страницы, в начале или в конце страницы, в ссылке, в метатэге и т.п.). Каждый поисковый механизм имеет свой алгоритм присваивания весовых коэффициентов - это одна из причин, по которой поисковые машины по одному и тому же ключевому слову выдают различные списки ресурсов. Поскольку страницы постоянно обновляются, процесс индексирования должен выполняться постоянно. Роботы-пауки путешествуют по ссылкам и формируют файл, содержащий индекс, который может быть довольно большим. Для уменьшения его размеров прибегают к минимизации объема информации и сжатию файла. Имея несколько роботов, поисковая система может обрабатывать сотни страниц в секунду. Сегодня мощные поисковые машины хранят сотни миллионов страниц и получают десятки миллионов запросов ежедневно.
При построении индекса решается также задача снижения количества дубликатов - задача нетривиальная, учитывая, что для корректного сравнения нужно сначала определить кодировку документа. Еще более сложной задачей является отделение очень похожих документов (их называют "почти дубликаты"), например таких, в которых отличается лишь заголовок, а текст дублируется. Подобных документов в Сети очень много - например, кто-то списал реферат и опубликовал его на сайте за своей подписью. Современные поисковые системы позволяют решать подобные проблемы.
Вопрос 8. Характеристики ИПС.
Основные характеристики поисковой системы
Опишем основные характеристики поисковых систем:
- Полнота
Полнота - одна из основных характеристик поисковой системы, представляющая собой отношение количества найденных по запросу документов к общему числу документов в сети Интернет, удовлетворяющих данному запросу. К примеру, если в Интернете имеется 100 страниц, содержащих словосочетание «как выбрать автомобиль», а по соответствующему запросу было найдено всего 60 из них, то полнота поиска будет 0,6. Очевидно, что чем полнее поиск, тем меньше вероятность того, что пользователь не найдет нужный ему документ, при условии, что он вообще существует в Интернете.
- Точность
Точность - еще одна основная характеристика поисковой машины, которая определяется степенью соответствия найденных документов запросу пользователя. Например, если по запросу «как выбрать автомобиль» находится 100 документов, в 50 из них содержится словосочетание «как выбрать автомобиль», а в остальных просто наличествуют эти слова («как правильно выбрать магнитолу и установить в автомобиль»), то точность поиска считается равной 50/100 (=0,5). Чем точнее поиск, тем быстрее пользователь найдет нужные ему документы, тем меньше различного рода «мусора» среди них будет встречаться, тем реже найденные документы не будут соответствовать запросу.
- Актуальность
Актуальность - не менее важная составляющая поиска, которая характеризуется временем, проходящим с момента публикации документов в сети Интернет, до занесения их в индексную базу поисковой системы. Например, на следующий день после появления интересной новости, большое количество пользователей обратились к поисковым системам с соответствующими запросами. Объективно с момента публикации новостной информации на эту тему прошло меньше суток, однако основные документы уже были проиндексированы и доступны для поиска, благодаря существованию у крупных поисковых систем так называемой «быстрой базы», которая обновляется несколько раз в день.
- Скорость поиска
Скорость поиска тесно связана с его устойчивостью к нагрузкам. Например, по данным Интернет Холдинг», на сегодняшний день в рабочие часы к поисковой машине Рамблер приходит около 60 запросов в секунду. Такая загруженность требует сокращения времени обработки отдельного запроса. Здесь интересы пользователя и поисковой системы совпадают: посетитель желает получить результаты как можно быстрее, а поисковая машина должна отрабатывать запрос максимально оперативно, чтобы не тормозить вычисление следующих запросов.
- Наглядность
Наглядность представления результатов является важным компонентом удобного поиска. По большинству запросов поисковая машина находит сотни, а то и тысячи документов. Вследствие нечеткости составления запросов или неточности поиска, даже первые страницы выдачи не всегда содержат только нужную информацию. Это означает, что пользователю зачастую приходится производить свой собственный поиск внутри найденного списка. Различные элементы страницы выдачи поисковой системы помогают ориентироваться в результатах поиска. одробные пояснения по странице результатов поиска, например у «Яндекса» можно посмотреть по ссылке
-Вопрос 10. Лингвистическое обеспечение ИПС.
Лингвистическое обеспечение - это логико-семантический аппарат, состоящий из информационно-поискового языка, правил применения (методик индексирования), критерия выдачи и других языковых средств.
-Вопрос 11. Информационно-поисковый язык ИПС. Структура. Типы и виды ИПЯ.
Информационно-поисковый язык системы
Однако, индекс - это только часть поискового аппарата, причем не видная глазу пользователя. Второй частью этого аппарата является информационно-поисковый язык. ИПЯ позволяет сформулировать запрос к системе в довольно простой и доходчивой форме. Уже давно осталась позади романтика создания ИПЯ, как естественного языка. Именно этот подход использовался в системе Wais на первых стадиях ее реализации. Если даже пользователю предлагается вводить запросы на естественном языке, то это не значит, что система будет осуществлять семантический разбор запроса пользователя. Проза жизни заключается в том, что обычно фраза разбивается на слова, из этого списка удаляются запрещенные и общие слова, иногда производится нормализация лексики, а затем все слова связываются либо логическим AND, либо OR. Таким образом запрос типа:
>Software that is used on Unix Platform
будет преобразован в:
>Unix AND Platform AND Software
что будет означать примерно следующее: "Найди все документы, в которых слова Unix, Platform и Software встречаются одновременно".
Возможны и варианты. Так в большинстве систем фраза "Unix Platform" будет опознана как ключевая фраза, и не будет разделяться на отдельные слова. Вообще говоря, и все три слова могут быть опознаны как одна ключевая фраза. Другой подход заключается в вычислении близости между запросом и документом. Именно этот подход используется в Lycos, например. В этом случае, в соответствии с векторной моделью представления документов и запросов вычисляется мера близости. К настоящему времени известно около дюжины различных мер близости. Наиболее часто применяется cos угла между поисковым образом документа и запросом пользователя. Именно эти проценты соответствия документа запросу и выдаются в качестве справочной информации при списке найденных документов.
Наиболее продвинутым языком запросов из современных информационно-поисковых систем Internet обладает AltaVista. Кроме обычного набора AND, OR, NOT, эта система позволяет использовать еще и NEAR. Последний оператор позволяет организовать контекстный поиск. Все документы в системе разбиты на поля, поэтому в запросе можно указать в какой части документа пользователь хочет увидеть ключевое слово (в ссылке, заголовке и т. п.). Можно также задать поле ранжирования выдачи и критерий близости документов запросу.
3.6.4. Типы информационно-поисковых языков
Главная задача информационно-поисковой системы - это поиск информации релевантной информационным потребностям пользователя. Слово релевантность означает соответствие между желаемой и действительно получаемой информацией. Релевантность можно еще представить как меру близости между реально полученными документами и тем, что следовало бы получить из системы. Естественно, что здесь возникает две задачи, которые следует решить: представление информации в системе и формулирование информационных потребностей пользователя. Эти две проблемы тесно связаны друг с другом. Руководства по многим информационно-поисковым системам Internet (Yahoo, OpenText и др.), что система реализует запрос типа "найди похожее". Но что значит эта фраза в реальности? Как вычислить эту самую похожесть?
Наиболее распространенными моделями представления документов в информационно-поисковой системе являются различные вариации на тему векторной модели, когда документ представляется как набор терминов. Как уже упоминалось ранее, это не весь текст документа, а только небольшой набор терминов, который отражает его содержание. Базируясь на таком представлении о документе и рассмотрим различные информационно-поисковые языки.
3.6.5. Традиционные информационно-поисковые языки и их модификации
Наиболее распространенным ИПЯ является язык, позволяющий составить логические выражения из набора терминов. При этом используются булевые операторы AND, OR, NOT. Запрос при этом может выглядеть следующим образом:
((информационная and система) or ИПС) not СУБД
В данном случае эта фраза означает: "Найди все документы, которые содержат одновременно слова "информационная" и "система", либо слово "ИПС", но не содержат слова "СУБД"".
Запрос можно рассматривать как и реальный документ из базы данных . В нашем случае, фактически, мы имеем дело с двумя запросами:
информационная and система not СУБД
ИПС not СУБД
каждый из которых подразумевает как бы два действия: сначала найти все документы, содержащие необходимые пользователю термины, а потом отсеять те, которые содержат термин "СУБД".
Такая схема достаточно проста, и поэтому наиболее широко применяется в современных информационно-поисковых системах. Но еще 20 лет тому назад были хорошо известны и ее недостатки.
Булевый поиск плохо масштабирует выдачу. Оператор AND может очень сильно сократить число документов, которые выдаются на запрос. При этом все будет очень сильно зависеть от того, насколько типичными для базы данных являются поисковые термины. Оператор OR напротив может привести к неоправданно широкому запросу, в котором полезная информация затеряется за информационным шумом. Для успешного применения этого ИПЯ следует хорошо знать лексику системы и ее тематическую направленность. Как правило, для системы с таким ИПЯ создаются специальные документально лексические базы данных со сложными словарями, которые называются тезаурусами и содержат информацию о связи терминов словаря друг с другом.
Модификацией булевого поиска является взвешенный булевый поиск. Идея такого поиска достаточно проста. Считается, что термин описывает содержание документа с какой-то точностью, и эту точность выражают в виде веса термина. При этом взвешивать можно как термины документа, так и термины запроса. Запрос может формулироваться на ИПЯ, описанном выше, но выдача документов при этом будет ранжироваться в зависимости от степени близости запроса и документа. При этом измерение близости строится таким образом, чтобы обычный булевый поиск был бы частным случаем взвешенного булевого поиска.
Языки типа "Like this"
При внимательном рассмотрении взвешенного поиска закрадывается естественное желание вообще обойтись без логических коннекторов и измерять близость документа и запроса какими-либо другими критериями. Наиболее простой моделью этого типа является линейная модель индексирования и поиска, когда близость документа и запроса рассматривается как угол между ними. В этом случае высчитывается sin угла, который получают как скалярное произведение двух векторов. В соответствии со значением меры близости происходит ранжирование документов при выдаче ссылок на них пользователю. Вообще говоря, скалярное произведение не очень хорошо подходит для информационно-поисковых систем Internet, так как длина запроса обычно невелика. Это в традиционных системах существовали специальные службы, которые отлаживали длинные запросы, а в Internet такие службы только нарождаются. Поэтому реально применяются другие меры близости, но принцип остается тот же: сначала вычисляется мера, а потом происходит ранжирование.
Рассмотренный подход дает возможность более мягкого расширения и уточнения запросов, но он также не гарантирует высоких показателей релевантности, в случае выбора неудачной лексики.
Поиск в нечетких множествах
При этом типе поиска весь массив документов описывается как набор нечетких множеств терминов. Каждый термин определяет некую монотонную функцию принадлежности документам документального массива. Когда запрашивается AND, то это интерпретируется как минимум из двух функций, соответствующих терминам запросов, OR - как максимум, NOT - как 1-<значение функции>. В соответствии с полученными значениями результат поиска также ранжируется, как и в случае с поиском по мерам близости.
Следует сразу сказать, что этот метод поиска используется только в исследовательских системах и распространен крайне ограничено.
-Вопрос 13. Интеллектуальные информационно-поисковые системы.
Структура интеллектуальной системы
С развитием компьютерных технологий менялся смысл, вкладываемый в понятие информационной системы. Современная информационная система - это набор информационных технологий , направленных на поддержку жизненного цикла информации и включающего три основных процесса: обработку данных, управление информацией и управление знаниями. В условиях резкого увеличения объемов информации переход к работе со знаниями на основе искусственного интеллекта является, по всей вероятности, единственной альтернативой информационного общества .
Согласно определению , "Система называется интеллектуальной, если в ней реализованы следующие основные функции:
- накапливать знания об окружающем систему мире, классифицировать и оценивать их с точки зрения прагматической полезности и непротиворечивости, инициировать процессы получения новых знаний, осуществлять соотнесение новых знаний с ранее хранимыми; пополнять поступившие знания с помощью логического вывода, отражающего закономерности в окружающем систему мире в накопленных ею ранее знаниях, получать обобщенные знания на основе более частных знаний и логически планировать свою деятельность; общаться с человеком на языке, максимально приближенном к естественному человеческому языку; получать информацию от каналов, аналогичных тем, которые использует человек при восприятии окружающего мира; уметь формировать для себя или по просьбе человека (пользователя) объяснение собственной деятельности; оказывать пользователю помощь за счет тех знаний, которые хранятся в памяти, и тех логических средств рассуждений, которые присущи системе".
Перечисленные функции можно назвать функциями представления и обработки знаний, рассуждения и общения. Наряду с обязательными компонентами, в зависимости от решаемых задач и области применения в конкретной системе эти функции могут быть реализованы в различной степени, что определяет индивидуальность архитектуры. На рис. 2.1 в наиболее общем виде представлена структура интеллектуальной системы в виде совокупности блоков и связей между ними .
База знаний представляет собой совокупность сред, хранящих знания различных типов. Рассмотрим кратко их назначение.
База фактов (данных) хранит конкретные данные, а база правил - элементарные выражения, называемые в теории искусственного интеллекта продукциями.
База процедур содержит прикладные программы, с помощью которых выполняются все необходимые преобразования и вычисления.
База закономерностей включает различные сведения, относящиеся к особенностям той среды, в которой действует система.
База метазнаний (база знаний о себе) содержит описание самой системы и способов ее функционирования: сведения о том, как внутри системы представляются единицы информации различного типа, как взаимодействуют различные компоненты системы, как было получено решение задачи.
База целей содержит целевые структуры, называемые сценариями, позволяющие организовать процессы движения от исходных фактов, правил, процедур к достижению той цели, которая поступила в систему от пользователя либо была сформулирована самой системой в процессе ее деятельности в проблемной среде.
Управление всеми базами, входящими в базу знаний, и организацию их взаимодействия осуществляет система управления базами знаний. С ее же помощью реализуются связи баз знаний с внешней средой. Таким образом, машина базы знаний осуществляет первую функцию интеллектуальной системы.
Выполнение второй функции обеспечивает часть интеллектуальной системы, называемая решателем и состоящая из ряда блоков, которые управляются системой управления решателя. Часть из блоков реализует логический вывод.
Блок дедуктивного вывода осуществляет в решателе дедуктивные рассуждения, с помощью которых из закономерностей из базы знаний, фактов из базы фактов и правил из базы правил выводятся новые факты. Кроме этого, данный блок реализует эвристические процедуры поиска решений задач как поиск путей решения задачи по сценариям при заданной конечной цели. Для реализации рассуждений, которые не носят дедуктивного характера, т. е. для поиска по аналогии, по прецеденту и т. д., используются блоки индуктивного и правдоподобного выводов.
Блок планирования применяется в задачах планирования решений совместно с блоком дедуктивного вывода.
Назначение блока функциональных преобразований состоит в решении задач расчетно-логического и алгоритмического типов.
disc"> интеллектуальные информационно-поисковые системы; экспертные системы (ЭС); расчетно-логические системы; гибридные экспертные системы.
Интеллектуальные информационно-поисковые системы являются системами взаимодействия с проблемно-ориентированными (фактографическими) базами данных на естественном, точнее ограниченном как грамматически, так и лексически (профессиональной лексикой) естественном языке (языке деловой прозы). Для них характерно использование (помимо базы знаний, реализующей семантическую модель представления знаний о проблемной области) лингвистического процессора.
Экспертные системы являются одним из бурно развивающихся классов интеллектуальных систем. Данные системы в первую очередь стали создаваться в математически слабоформализованных областях науки и техники, таких как медицина, геология, биология и другие. Для них характерна аккумуляция в системе знаний и правил рассуждений опытных специалистов в данной предметной области, а также наличие специальной системы объяснений.
Расчетно-логические системы позволяют решать управленческие и проектные задачи по их постановкам (описаниям) и исходным данным вне зависимости от сложности математических моделей этих задач. При этом конечному пользователю предоставляется возможность контролировать в режиме диалога все стадии вычислительного процесса. В общем случае, по описанию проблемы на языке предметной области обеспечивается автоматическое построение математической модели и автоматический синтез рабочих программ при формулировке функциональных задач из данной предметной области. Эти свойства реализуются благодаря наличию базы знаний в виде функциональной семантической сети и компонентов дедуктивного вывода и планирования.
В последнее время в специальный класс выделяются гибридные экспертные системы. Указанные системы должны вобрать в себя лучшие черты как экспертных, так и расчетно-логических и информационно-поисковых систем. Разработки в области гибридных экспертных систем находятся на начальном этапе.
Наиболее значительные успехи в настоящее время достигнуты в таком классе интеллектуальных систем, как экспертные системы.
Важное место в теории искусственного интеллекта (ИИ) занимает проблема представления знаний. В настоящее время выделяют следующие основные типы моделей представления знаний:
- семантические сети, в том числе функциональные; фреймы и сети фреймов; продукционные модели.
Семантические сети определяют как граф общего вида, в котором можно выделить множество вершин и ребер. Каждая вершина графа представляет некоторое понятие, а дуга - отношение между парой понятий. Метка и направление дуги конкретизируют семантику. Метки вершин семантической нагрузки не несут, а используются как справочная информация.
Различные разновидности семантических сетей обладают различной семантической мощностью, следовательно, можно описать одну и ту же предметную область более компактно или громоздко.
Фреймом называют структуру данных для представления и описания стереотипных объектов, событий или ситуаций. Фреймовая модель представления знаний состоит из двух частей:
- набора фреймов, составляющих библиотеку внутри представляемых знаний; механизмов их преобразования, связывания и т. д. Существует два типа фреймов: образец (прототип) - интенсиональное описание некоторого множества экземпляров; экземпляр (пример) - экстенсиональное представление фрейм-образца.
В общем виде фрейм может быть представлен следующим кортежем:
<ИФ, (ИС, ЗС, ПП),..., (ИС, ЗС, ПП)>,
где ИФ - имя фрейма; ИС - имя слота; ЗС - значение слота; ПП - имя присоединенной процедуры (необязательный параметр).
Слоты - это некоторые незаполненные подструктуры фрейма, заполнение которых приводит к тому, что данный фрейм ставится в соответствие некоторой ситуации, явлению или объекту.
В качестве данных фрейм может содержать обращения к процедурам (так называемые присоединенные процедуры). Выделяют два вида процедур: процедуры-демоны и процедуры-слуги. Процедуры-демоны активизируются при каждой попытке добавления или удаления данных из слота. Процедуры-слуги активизируются только при выполнении условий, определенных пользователем при создании фрейма.
Продукционные модели - это набор правил вида "условия-действие", где условиями являются утверждения о содержимом базы данных, а действия представляют собой процедуры, которые могут изменять содержимое базы данных.
Формально продукция определяется следующим образом:
(i); Q;P;С; QA В; N,
где (i) - имя продукции (правила); Q - сфера применения правила; Р - предусловие (например, приоритетность); С - предикат (отношение); А -> В - ядро; N - постусловия (изменения, вносимые в систему правил).
Практически продукции строятся по схеме "ЕСЛИ" (причина или, иначе, посылка), "ТО" (следствие или, иначе, цель правила).
Полученные в результате срабатывания продукций новые знания могут использоваться в следующих целях:
- понимание и интерпретация фактов и правил с применением продукций, фреймов, семантических цепей; решение задач с помощью моделирования; идентификация источника данных, причин несовпадений новых знаний со старыми, получение метазнаний; составление вопросов к системе; усвоение новых знаний, устранение противоречий, систематизация избыточных данных.
Процесс рассмотрения компьютером набора правил (выполнение программы) называют консультацией. Ее наиболее удобная для пользователя форма - дружественный диалог с компьютером. Интерфейс может быть в форме меню, на языке команд и на естественном языке.
Диалог может быть построен на системе вопросов, задаваемых пользователем, компьютером, или фактов - данных, хранящихся в базе данных. Возможен смешанный вариант, когда в базе данных недостаточно фактов.
При прямом поиске пользователь может задавать две группы вопросов, на которые компьютер дает объяснения:
- как получено решение. При этом компьютер должен выдать на экран трассу в виде ссылок на использованные правила; почему компьютер задал какой-то вопрос. При этом на экран выдается своеобразная трасса, которую компьютер хотел бы использовать для вывода после получения ответа на задаваемый вопрос. Вопрос почему может быть задан как в процессе консультации, так и после выполнения программы.
Специфичен алгоритм поиска, реализуемый логическими языками: он является фактически последовательным перебором по дереву сверху вниз - слева направо.
Чтобы пользоваться предварительным просмотром презентаций создайте себе аккаунт (учетную запись) Google и войдите в него: https://accounts.google.com
Подписи к слайдам:
Обзор функционала современных поисковых систем Шукшин Е. В.
Поисковая система - это программно-аппаратный комплекс, предназначенный для осуществления поиска в сети Интернет и реагирующий на запрос пользователя, задаваемый в виде текстовой фразы (поискового запроса), выдачей списка ссылок на источники информации, в порядке релевантности (в соответствии запросу). международные поисковые системы: « Google », « Yahoo », «MSN». В русском Интернете это – «Яндекс», «Рамблер», «Апорт».
Основные характеристики поисковых систем: Полнота Точность Актуальность Скорость поиска Наглядность
Компоненты поисковой системы: Модуль индексирования spider crawler indexer База данных Поисковый сервер
Первой полноценной поисковой системой стал проект WebCrawler, вышедший в свет в 1994 году. В 1995 году появились поисковые системы Lycos и AltaVista . В 1997 году Сергей Брин и Ларри Пейдж создали поисковую машину Google в рамках исследовательского проекта в Стэндфордском университете В сентябре 1997 года была официально анонсирована поисковая система Yandex .
Предварительный просмотр:
МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ РФ
ФЕДЕРАЛЬНОЕ ГОСУДАРСТВЕННОЕ БЮДЖЕТНОЕ
ОБРАЗОВАТЕЛЬНОЕ УЧРЕЖДЕНИЕ ВЫСШЕГО
ОБРАЗОВАНИЯ «МОРДОВСКИЙ ГОСУДАРСТВЕННЫЙ
ПЕДАГОГИЧЕСКИЙ ИНСТИТУТ
ИМЕНИ М.Е. ЕВСЕВЬЕВА»
Физико-математический факультет
Кафедра информатики и вычислительной техники
Реферат
ОБЗОР ФУНКЦИОНАЛА СОВРЕМЕННЫХ ПОИСКОВЫХ СИСТЕМ
Саранск 2017
Введение
Поисковые системы уже давно стали неотъемлемой частью российского Интернета. Поисковые системы сейчас – это огромные и сложные механизмы, представляющие собой не только инструмент поиска информации, но и заманчивые сферы для бизнеса.
Большинство пользователей поисковых систем никогда не задумывались (либо задумывались, но не нашли ответа) о принципе работы поисковых систем, о схеме обработки запросов пользователей, о том, из чего эти системы состоят и как функционируют…
1. Понятие и функции поисковой системы
Поисковая система - это программно-аппаратный комплекс, предназначенный для осуществления поиска в сети Интернет и реагирующий на запрос пользователя, задаваемый в виде текстовой фразы (поискового запроса), выдачей списка ссылок на источники информации, в порядке релевантности (в соответствии запросу). Наиболее крупные международные поисковые системы: «Google» , «Yahoo» , «MSN» . В русском Интернете это – «Яндекс» , «Рамблер» , «Апорт» .
Рассмотрим подробнее понятие поискового запроса на примере поисковой системы «Яндекс». Поисковый запрос должен быть сформулирован пользователем в соответствии с тем, что он хочет найти, максимально кратко и просто. Допустим, мы хотим найти информацию в «Яндексе» о том, как выбрать автомобиль. Для этого, открываем главную страницу «Яндекса», и вводим текст поискового запроса «как выбрать автомобиль». Далее, наша задача сводится к тому, чтобы открыть предоставленные по нашему запросу ссылки на источники информации в Интернет. Однако, вполне можно и не найти нужную нам информацию. Если таковое произошло, то либо нужно перефразировать свой запрос, либо в базе поисковой системе действительно нет никакой актуальной информации по нашему запросу (такое может быть при задании очень «узких» запросов, как, например «как выбрать автомобиль в Архангельске»)
Первоочередная задача любой поисковой системы – доставлять людям именно ту информацию, которую они ищут. А научить пользователей делать «правильные» запросы к системе, т.е. запросы, соответствующие принципам работы поисковых систем, невозможно. Поэтому разработчики создают такие алгоритмы и принципы работы поисковых систем, которые бы позволяли находить пользователям искомую ими информацию.
Рис. 1. – Результаты поиска по запросу
Это означает, поисковая система должна «думать» так же, как думает пользователь при поиске информации. Когда пользователь обращается с запросом к поисковой машине, он хочет найти то, что ему нужно, максимально быстро и просто. Получая результат, он оценивает работу системы, руководствуясь несколькими основными параметрами. Нашел ли он то, что искал? Если не нашел, то сколько раз ему пришлось перефразировать запрос, чтобы найти искомое? Насколько актуальную информацию он смог найти? Насколько быстро обрабатывала запрос поисковая машина? Насколько удобно были представлены результаты поиска? Был ли искомый результат первым или же сотым? Как много ненужного мусора было найдено наравне с полезной информацией? Найдется ли нужная информация, при обращении к поисковой системе, скажем, через неделю, или через месяц?
Для того, чтобы удовлетворить ответами все эти вопросы, разработчики поисковых машин постоянно совершенствуют алгоритмы и принципы поиска, добавляют новые функции и возможности, всячески пытаются ускорить работу системы.
2. Основные характеристики поисковой системы
Опишем основные характеристики поисковых систем:
- Полнота
- Полнота - одна из основных характеристик поисковой системы, представляющая собой отношение количества найденных по запросу документов к общему числу документов в сети Интернет, удовлетворяющих данному запросу. К примеру, если в Интернете имеется 100 страниц, содержащих словосочетание «как выбрать автомобиль», а по соответствующему запросу было найдено всего 60 из них, то полнота поиска будет 0,6. Очевидно, что чем полнее поиск, тем меньше вероятность того, что пользователь не найдет нужный ему документ, при условии, что он вообще существует в Интернете.
- Точность
- Точность - еще одна основная характеристика поисковой машины, которая определяется степенью соответствия найденных документов запросу пользователя. Например, если по запросу «как выбрать автомобиль» находится 100 документов, в 50 из них содержится словосочетание «как выбрать автомобиль», а в остальных просто наличествуют эти слова («как правильно выбрать магнитолу и установить в автомобиль»), то точность поиска считается равной 50/100 (=0,5). Чем точнее поиск, тем быстрее пользователь найдет нужные ему документы, тем меньше различного рода «мусора» среди них будет встречаться, тем реже найденные документы не будут соответствовать запросу.
- Актуальность
- Актуальность - не менее важная составляющая поиска, которая характеризуется временем, проходящим с момента публикации документов в сети Интернет, до занесения их в индексную базу поисковой системы. Например, на следующий день после появления интересной новости, большое количество пользователей обратились к поисковым системам с соответствующими запросами. Объективно с момента публикации новостной информации на эту тему прошло меньше суток, однако основные документы уже были проиндексированы и доступны для поиска, благодаря существованию у крупных поисковых систем так называемой «быстрой базы», которая обновляется несколько раз в день.
- Скорость поиска
- Скорость поиска тесно связана с его устойчивостью к нагрузкам. Например, по данным ООО «Рамблер Интернет Холдинг», на сегодняшний день в рабочие часы к поисковой машине Рамблер приходит около 60 запросов в секунду. Такая загруженность требует сокращения времени обработки отдельного запроса. Здесь интересы пользователя и поисковой системы совпадают: посетитель желает получить результаты как можно быстрее, а поисковая машина должна отрабатывать запрос максимально оперативно, чтобы не тормозить вычисление следующих запросов.
- Наглядность
- Наглядность представления результатов является важным компонентом удобного поиска. По большинству запросов поисковая машина находит сотни, а то и тысячи документов. Вследствие нечеткости составления запросов или неточности поиска, даже первые страницы выдачи не всегда содержат только нужную информацию. Это означает, что пользователю зачастую приходится производить свой собственный поиск внутри найденного списка. Различные элементы страницы выдачи поисковой системы помогают ориентироваться в результатах поиска. Подробные пояснения по странице результатов поиска, например у «Яндекса» можно посмотреть по ссылке http://help.yandex.ru/search/?id=481937 .
3. Краткая история развития поисковых систем
В начальный период развития Интернет, число его пользователей было невелико, а объем доступной информации сравнительно небольшим. В большинстве своем, доступ к сети Интернет имели лишь сотрудники научно-исследовательской сферы. В это время задача поиска информации в Интернете не была столь актуальной, как в настоящее время.
Одним из первых способов организации доступа к информационным ресурсам сети стало создание открытых каталогов сайтов, ссылки на ресурсы в которых группировались согласно тематике. Первым таким проектом стал сайт Yahoo.com, открывшийся весной 1994 года. После того, как количество сайтов в каталоге значительно увеличилось, была добавлена возможность поиска нужной информации по каталогу. В полном смысле это еще не было поисковой системой, так как поисковая область была ограничена только ресурсами, присутствующими в каталоге, а не всеми Интернет ресурсами.
Каталоги ссылок широко использовались ранее, однако практически полностью утратили свою популярность в настоящее время. Так как даже современные, огромные по своему объему каталоги, содержат информацию лишь о ничтожно малой части сети Интернет. Самый большой каталог сети DMOZ (его еще называют Open Directory Project) содержит информацию о 5 миллионах ресурсов, тогда как база поисковой системы Google состоит из более чем 8 миллиардов документов.
В 1995 году появились поисковые системы Lycos и AltaVista. Последняя долгие годы была лидером в области поиска информации в сети Интернет.
В 1997 году Сергей Брин и Ларри Пейдж создали поисковую машину Google в рамках исследовательского проекта в Стэндфордском университете. В настоящий момент Google - самая популярная поисковая система в мире!
В сентябре 1997 года была официально анонсирована поисковая система Yandex, являющаяся самой популярной в русскоязычном Интернете.
В настоящее время существуют три основные поисковые системы (международные) – Google, Yahoo и , имеющие собственные базы и алгоритмы поиска. Большинство остальных поисковых систем (коих насчитывается большое количество) использует в том или ином виде результаты трех перечисленных. Например, поиск AOL (search.aol.com) использует базу Google, а AltaVista, Lycos и AllTheWeb – базу Yahoo.
4. Состав и принципы работы поисковой системы
В России основной поисковой системой является «Яндекс», далее - Rambler.ru, Google.ru, Aport.ru, Mail.ru. Причем, на данный момент, Mail.ru использует механизм и базу поиска «Яндекса».
Практически все крупные поисковые системы имеют свою собственную структуру, отличную от других. Однако можно выделить общие для всех поисковых машин основные компоненты. Различия в структуре могут быть лишь в виде реализации механизмов взаимодействия этих компонентов.
Модуль индексирования
Модуль индексирования состоит из трех вспомогательных программ (роботов):
Spider (паук) – программа, предназначенная для скачивания веб-страниц. «Паук» обеспечивает скачивание страницы и извлекает все внутренние ссылки с этой страницы. Скачивается html-код каждой страницы. Для скачивания страниц роботы используют протоколы HTTP. Работает «паук» следующим образом. Робот на сервер передает запрос “get/path/document” и некоторые другие команды HTTP-запроса. В ответ робот получает текстовый поток, содержащий служебную информацию и непосредственно сам документ.
Ссылки извлекаются из тэгов a, area, base, frame, frameset, и др. Наряду со ссылками, многими роботами обрабатываются редиректы (перенаправления). Каждая скачанная страница сохраняется в следующем формате:
- URL страницы
- дата, когда страница была скачана
- http-заголовок ответа сервера
- тело страницы (html-код)
Crawler («путешествующий» паук) – программа, которая автоматически проходит по всем ссылкам, найденным на странице. Выделяет все ссылки, присутствующие на странице. Его задача - определить, куда дальше должен идти паук, основываясь на ссылках или исходя из заранее заданного списка адресов. Crawler, следуя по найденным ссылкам, осуществляет поиск новых документов, еще неизвестных поисковой системе.
Indexer (робот- индексатор) - программа, которая анализирует веб-страницы, скаченные пауками. Индексатор разбирает страницу на составные части и анализирует их, применяя собственные лексические и морфологические алгоритмы. Анализу подвергаются различные элементы страницы, такие как текст, заголовки, ссылки структурные и стилевые особенности, специальные служебные html-теги и т.д.
Таким образом, модуль индексирования позволяет обходить по ссылкам заданное множество ресурсов, скачивать встречающиеся страницы, извлекать ссылки на новые страницы из получаемых документов и производить полный анализ этих документов.
База данных
База данных, или индекс поисковой системы - это система хранения данных, информационный массив, в котором хранятся специальным образом преобразованные параметры всех скачанных и обработанных модулем индексирования документов.
Поисковый сервер
Поисковый сервер является важнейшим элементом всей системы, так как от алгоритмов, которые лежат в основе ее функционирования, напрямую зависит качество и скорость поиска.
Поисковый сервер работает следующим образом:
- Полученный от пользователя запрос подвергается морфологическому анализу. Генерируется информационное окружение каждого документа, содержащегося в базе.
- Полученные данные передаются в качестве входных параметров специальному модулю ранжирования. Происходит обработка данных по всем документам, в результате чего, для каждого документа рассчитывается собственный рейтинг, характеризующий релевантность запроса, введенного пользователем, и различных составляющих этого документа, хранящихся в индексе поисковой системы.
- В зависимости от выбора пользователя этот рейтинг может быть скорректирован дополнительными условиями (например, так называемый «расширенный поиск»).
- Далее генерируется сниппет, то есть, для каждого найденного документа из таблицы документов извлекаются заголовок, краткая аннотация, наиболее соответствующая запросу и ссылка на сам документ, причем найденные слова подсвечиваются.
- Полученные результаты поиска передаются пользователю в виде SERP (Search Engine Result Page) – страницы выдачи поисковых результатов.
Как видно, все эти компоненты тесно связаны друг с другом и работают во взаимодействии, образовывая четкий, достаточно сложный механизм работы поисковой системы, требующий огромных затрат ресурсов.
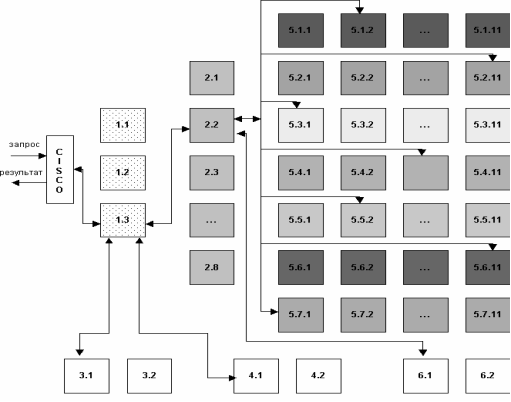
По информации ООО «Рамблер Интернет Холдинг» обработка поискового запроса в системе «Рамблер» происходит, так, как это изображено на рисунке.
Рис. 2 – Обработка поискового запроса в системе «Рамблер»
Запрос поступает в поисковую систему через маршрутизатор Cisco 6000 series. Cisco передает его наименее загруженной машине первого уровня - frontend (1.1 - 1.3, на рис. машине 1.3). Frontend, в свою очередь, отправляет запрос дальше, на один из восьми proxy-серверов, также выбирая наиболее свободный сервер (2.1 - 2.8, на рис. машине 2.2). Одновременно frontend отправляет запрос на машины, осуществляющие поиск по товарам (3.1 - 3.2, на рис. машине 3.1) и по базе Тор 100 (4.1 - 4.2, на рис. машине 4.1). На proxy проводится поиск по ссылочному индексу, и его результаты вместе с поисковым запросом передаются на машины, которые содержат основную индексную базу, - backends (5.1.х - 5.7.х, на рис. машинам 5.1.2, 5.2.11, 5.3.1 и т.д.) Та же информация отправляется на машины с "быстрой базой" (6.1 - 6.2).
На текущий момент в поиск включено 77 backend"ов. Они сгруппированы по 11 машин, и каждая группа содержит копию одной из частей поискового индекса. Таким образом, информация о сайтах, условно входящих в красный сектор Интернета, находится на backend"ах первой группы (5.1.1 - 5.1.11 на рис), оранжевый сектор - на backend"ах второй группы (5.2.1 - 5.2.11) и т.д. Proxy-сервер выбирает наименее загруженный backend в каждой группе машин и отправляет на него поисковый запрос с результатами ссылочного поиска. На backend"ах осуществляется поиск по частям индексной базы и ранжирование с учетом результатов поиска по ссылочному индексу. При ранжировании для всех найденных документов высчитываются веса по конкретному запросу.
После того, как запрос обработан на backend"ах, информация о результатах и ранжировании отдается обратно на proxy-сервер. Туда же поступают отсортированные результаты с машин "быстрой базы". Proxy интегрирует данные, полученные с восьми машин: клеит дубли, объединяет зеркала сайтов, переранжирует документы в общий список по весам, рассчитанным на backend"ах. Так, первым в списке найденного может быть документ с машины 5.3.1, вторым и третьим - с 6.1, четвертым - с 5.5.2 и т.д. На proxy-сервере также реализуется построение цитат к документам и подсветка слов запроса в тексте. Полученные результаты отдаются на frontend.
Помимо информации с proxy-сервера, frontend получает результаты из поиска по товарам и из базы Тор 100, отсортированные, с цитатами и подсветкой слов запроса. Frontend осуществляет окончательное объединение результатов, генерирует html со списком найденного, вставляет баннеры и перевязки (ссылки на различные разделы Рамблера) и отдает html Cisco, который маршрутизирует информацию пользователю.
Заключение
Теперь подытожим все вышесказанное. Первоочередная задача любой поисковой системы – доставлять людям именно ту информацию, которую они ищут. Основные характеристики поисковых систем:
- Полнота
- Точность
- Актуальность
- Скорость поиска
- Наглядность
Первой полноценной поисковой системой стал проект WebCrawler, вышедший в свет в 1994 году.
В состав поисковой системы входят компоненты:
- Модуль индексирования
- База данных
- Поисковый сервер
Список использованных источников
- Гусев, В.С. Google. Эффективный поиск – Москва: Диалектика, 2010г., 231с.
- Егоров, А.Б. Поиск в Интернете - Санкт - Петербург.: НиТ, 2010г. 119с.
- Несколько слов о том, как работают роботы поисковых машин // Citforum URL: http://www.citforum.ru/internet/search/art_1. shtm (дата обращения: 01.03.2017).
- Поиск и навигация в Internet // Открытые системы URL: http://www.osp.ru/cw/1996/20/31.htm (дата обращения: 01.03.2017).
- Рассел, С. Интеллектуальные системы – М.: Вильямс, 2007. – 1408 с.
- Экслер, А.Б. Самоучитель работы в Интернете - Москва.: NT Press, 2010г. 542с.
- Введение 2
- Глава I. Теоретическая часть 4
- 1.1 Краткая история развития поисковых систем 4
- 1.2 Рейтинг основных мировых поисковых систем 5
- 1.3 Рейтинг основных Российских поисковых систем 6
- 1.4 Обзор основных мировых поисковых систем 7
- 1.4.1 Google 7
- 1.4.2 Yahoo 9
- 1.4.3 Baidu 10
- 1.5 Обзор основных Российских поисковых систем 11
- 1.5.1 Yandex 11
- 1.5.2 Rambler 13
- 1.5.3 Апорт 13
- 1.5.4 Mail.ru 15
- Глава II. Обработка информации в маркетинговом исследовании 17
- 2.1 Текстовый процессор Microsoft Word 17
- 2.2 Табличный редактор Excel 17
- 2.3 Редактор Microsoft Power Point 17
- Глава III . Организация рабочего места оператора ЭВМ 19
- 3.1 Общие требования безопасности 19
- 3.2 Требования безопасности перед началом работы 20
- 3.3 Требования безопасности во время работы 20
- 3.4 Требования безопасности в аварийных ситуациях 21
- Заключение 22
- Список литературы 23
- Введение
- Всемирная сеть очень важна и полезна практически для любого! Каждый пользователь Интернета может найти в нем массу разнообразной и интереснейшей информации, а также использовать все богатейшие возможности сети. Для меня решающими обстоятельствами в выборе темы «Обзор современных поисковых систем в интернете», для своей квалификационной работы, стала во-первых достаточная известность мне этой темы, в силу частого посещения мной всемирной сети, а также актуальность темы на сегодняшний день. Ресурсы Интернета давно перестали быть просто игрушкой, превратившись в незаменимый инструмент для повседневной работы людей многих профессий. Быстрый рост информации в сети сделали его океаном разнообразнейших данных, важность которых растет пропорционально их объему. По оценке экспертов объем информации, передаваемой по каналам Интернет, удваивается каждые полгода. Ежедневно в сети появляются миллионы новых документов, и естественно, что без систем поиска они в подавляющем своем большинстве остались бы не востребованными, вообще не были бы не кем найдены, и все то огромное количество информации оказалось бы никому не нужным. Возникла необходимость создания таких средств, которые позволили бы легко ориентироваться в информационных ресурсах глобальных сетей, быстро и надежно находить нужные сведения. В интернете появились специальные поисковые средства. Еще несколько лет назад бытовало такое мнение: в Интернете есть все, но найти там ничего невозможно. Однако с появлением и быстрым развитием поисковых каталогов, поисковых машин, и всевозможных поисковых программ ситуация изменилась, и теперь в Сети срочно понадобившуюся информацию иногда можно найти быстрее, чем в книге, лежащей на столе.
- Наиболее популярным и используемым способом поиска в Интернете является использование поисковых систем. Что же такое поисковая система? Поисковая система - портал, осуществляющий поиск, сбор и сортировку информации в сети Интернет. Поисковые системы это инструмент, позволяющий пользователю глобальной сети в кратчайшие сроки найти интересующую его информацию.
- Первоочередная задача любой поисковой системы - доставлять людям именно ту информацию, которую они ищут.
- Получая результат, пользователь оценивает работу системы, руководствуясь несколькими основными параметрами. Нашел ли он то, что искал? Если не нашел, то сколько раз ему пришлось перефразировать запрос, чтобы найти искомое? Насколько актуальную информацию он смог найти? Насколько быстро обрабатывала запрос поисковая машина? Насколько удобно были представлены результаты поиска? Был ли искомый результат первым или же сотым? Как много ненужного мусора было найдено наравне с полезной информацией? Найдется ли нужная информация, при обращении к поисковой системе, скажем, через неделю, или через месяц?
Моя работа имеет следующую структуру:
1) Введение.
2) I глава - включает в себя краткую историю развития поисковых систем, основных поисковых систем, а также обзор основных мировых и российских поисковиков.
3) II глава - методы использования компьютерных программ и аппаратных средств для маркетинговых исследований.
4) III глава - включает в себя организацию рабочего места оператора ЭВМ и технику безопасности и охрану труда на рабочем месте.
5) Заключение - общие выводы по всей квалификационной работе, а так же точку зрения автора о том какими поисковиками лучше всего пользоваться.
6) Список литературы.
Глава I. Теоретическая часть
1.1 Краткая история развития поисковых систем
Одним из первых способов организации доступа к информационным ресурсам сети стало создание каталогов сайтов, в которых ссылки на ресурсы группировались согласно тематике. Первым таким проектом стал сайт Yahoo, открывшийся в апреле 1994 года. После того, как число сайтов в каталоге Yahoo значительно увеличилось, была добавлена возможность поиска информации по каталогу. Это, конечно же, не было поисковой системой в полном смысле, так как область поиска была ограничена только ресурсами, присутствующими в каталоге, а не всеми ресурсами сети Интернет.
Каталоги ссылок широко использовались ранее, но практически утратили свою популярность в настоящее время. Причина этого очень проста - даже современные каталоги, содержащие огромное количество ресурсов, представляют информацию лишь об очень малой части сети Интернет. Самый большой каталог сети DMOZ (или Open Directory Project) содержит информацию о 5 миллионах ресурсов, в то время как база поисковой системы Google состоит из более чем 8 миллиардов документов.
Первой полноценной поисковой системой стал проект WebCrawler появившийся в 1994 году.
В 1995 году появились поисковые системы Lycos и AltaVista. Последняя долгие годы была лидером в области поиска информации в Интернет.
В 1997 году Сергей Брин и Лари Пейдж создали Google самую популярную на сегодняшний момент поисковую систему в мире.
23 сентября 1997 года была официально анонсирована поисковая система Yandex, самая популярная в русскоязычной части Интернет.
В настоящее время существует 3 основных международных поисковых системы - Google, Yahoo и MSN Search, имеющих собственные базы и алгоритмы поиска. Большинство остальных поисковых систем (коих можно насчитать очень много) использует в том или ином виде результаты 3 перечисленных. Например, поиск AOL (search.aol.com) и Mail.ru используют базу Google, а AltaVista, Lycos и AllTheWeb - базу Yahoo.
В России основной поисковой системой является Яндекс, за ним идут Rambler, Google.ru, Aport, Mail.ru и КМ.ru
По данным исследования про водившегося на конец 2007 года доминирующие место в рейтинге стабильно занимает компания Google. В декабре на долю гиганта пришлось 41,3 миллиардов поисковых запросов, это - 62,4% рынка. Второе место (с большим отрывом) у Yahoo! - 8,5 миллиардов запросов, 12,8% рынка и крупнейшего китайского поисковика Baidu.com - 3,4 млрд. запросов, 5,2% рынка. К слову, уверенные позиции последнего связаны с тем, что на территории Китая заблокированы и Google, и Yahoo!
|
Название поисковой системы |
Число запросов, миллионов . |
Доля, процентов |
|
|
Всего в интернете |
|||
|
Time Warner Network |
|||
На сегодняшний день самой популярной русскоязычной пои сковой системой является Яндекс - 54% всех поисковых запросов.
1.4 Обзор основных мировых поисковых систем
На сегодняшний день всемирная сеть Интернет насчитывает огромное множество поисковых систем во всех странах мира, из них всех можно выделить несколько самых крупных и пользующихся наибольшей популярностью среди пользователей:
1.4.1 Google
Лидер поисковых машин Интернета, Google занимает более 60 % мирового рынка, а значит, шесть из десяти находящихся в сети людей обращаются к его странице в поисках информации в Интернете. Сейчас регистрирует ежедневно около 50 миллионов поисковых запросов и индексирует более 8 миллиардов веб-страниц.
Была разработана в 1998 выпускниками Стэндфордского университета Сергеем Брином и Лари Пейджем, которые применили для ранжирования документов технологию PageRank, где одним из ключевых моментов является определение "авторитетности" конкретного документа на основе информации о документах, ссылающихся на него. Говоря общими словами, чем больше документов ссылается на данный документ и чем они авторитетнее, тем более авторитетным данный документ становится. Количественное значение авторитетности документа (другими словами, взвешенное количество ссылок или PageRank) относится к так называемым статическим факторам (то есть независящим от конкретного запроса) и учитывается при определении релевантности документа конкретному запросу как весовой коэффициент. Наряду с этим Google применил для определения релевантности документа не только текст самого документа, но и текст ссылок на него. Эта технология позволила ему обеспечить выдачу довольно релевантных результатов на фоне других поисковиков. Довольно быстро Google стал лидировать в различных опросах по такому показателю, как удовлетворенность пользователей результатами поиска.
Google осуществляет поиск по документам на более чем 35 языках, в том числе русском. В настоящее время многие порталы и специализированные сайты предоставляют услуги поиска информации в Интернете на базе Google, что делает задачу успешного позиционирования сайтов в Google еще более важной. Google проводит переиндексацию своей поисковой базы примерно раз в четыре недели. Во время этого усовершенствования, неофициально называемого Google dance, происходит обновление базы на основе информации, собранной роботами за время, прошедшее с предыдущего усовершенствования, и перерасчет значений PageRank документов. Также существует определенное количество документов с достаточно большим значением PageRank, информация о которых в поисковой базе обновляется ежедневно, однако значение PageRank пересчитывается только во время Google dance. Нормированное значение PageRank для конкретного документа, загруженного в браузер, можно узнать, скачав и установив Google ToolBar - специальную панель инструментов для работы с этим поисковиком. Не смотря на то, что в поисковике имеется форма для бесплатного добавления страницы в базу, Google предпочитает сам находить новые документы по ссылкам с уже известных и не будет индексировать добавленную через форму страницу, если в его базе не найдется ни одной страницы, ссылающейся на нее.
1.4.2 Yahoo
Одна из самых первых Поисковых систем (создана Дэвидом Фило и Джерри Янгом в апреле 1994года) по сей день остается и самой популярной из них, традиционно сочетая поиск, как по ключевым словам, так и с помощью иерархического дерева разделов.
Нынешнее развитие Yahoo можно определить как движение в он-лайн, интерактивность. Yahoo быстро осваивает эту область Интернет-услуг, но возникает одна проблема: ядро Yahoo! не было на это рассчитано. Не была в 1994 году заложено в него "онлайновая" составляющая, ее "приклеил" Тим Кугл несколькими годами позже. Естественно возникает угроза хакерских атак через эту незащищенную область.
Одно из новшеств поисковой системы Yahoo - панель задач для браузера Firefox,. Этот инструмент помогает пользоваться поиском Yahoo, не заходя на официальный сайт, а лишь используя функциональные кнопки панели.
1 сентября 2005 года поисковик Yahoo, которому принадлежит более 200 миллионов адресов электронной почты по всему миру, анонсировал запуск новой системы поиска текстов, фотографий и других документов, содержащихся в письмах.
Необходимость такого нововведения возникла вслед за увеличением объёма хранимых данных, ведь некоторые пользователи создают целые почтовые архивы. Подгоняемый конкурентом Google и его почтовым сервисом Gmail, Yahoo для хранения почты предлагает отныне 1 гигабайт бесплатного места, или 2 гигабайта по годовому абонементу. "Как только вы получаете возможность хранить больше информации, вам необходимы и расширенные поисковые возможности", - объясняет Эрик Петерсон, аналитик компании Jupiter Research.
Пользователи поисковой системы Yahoo, в свою очередь, смогут теперь использовать возможности детализированного поиска слов в названии или непосредственно в тексте письма, а также в присоединенных документах, не открывая их. Результат поиска отражается в трёх строках с указанием всех атрибутов. На панели справа отображаются все похожие документы. Найденные фотографии выводятся на экран в уменьшенном виде, что значительно облегчает поиск. Система также учитывает орфографические ошибки, позволяя искать слова лишь по первым буквам.
Для начала Yahoo планирует предложить новую систему небольшому числу американских пользователей, а затем распространить её по всему миру. Со стороны клиентов это не потребует никаких дополнительных усилий. "Когда услуга станет, доступна, в левом верхнем углу страницы вашего почтового ящика появится соответствующий баннер", - обещает компания Yahoo.
По данным comScore Media Metrix на июль этого года, домену Yahoo принадлежит 219 миллионов адресов электронной почты, что составляет 31,5% мирового рынка, уступая лишь Microsoft с 221 миллионом пользователей сервиса Hotmail (35,5% рынка).
1.4.3 Baidu
Baidu - лидер среди китайских поисковых систем. По количеству обрабатываемых запросов поисковый сайт Байду стоит на 3 месте в мире (3 миллиарда 428 миллионов; с долей в глобальном поиске 5,2 %). Хотя компания работает только в единственной стране: Китае! Но точно, что этот рынок растет неистово быстро: Уже в конце года в Китае свыше 170 млн. пользователей займутся поиском информации в Интернете. Аналитик J.P. Морган Дик Вей исходит в своем актуальном анализе из того, что это число вырастет в течение следующих трех, четырех лет до 100 млн. пользователей. Гигантский рынок с экстремально высокими доходами для Baidu. Сравнивают только прибыль, которую Google достигает в США с очень похожей бизнес-моделью.
1.5 Обзор основных Российских поисковых систем
Основное отличие русскоязычных поисковых систем от иностранных одно - это то, что глобальные поисковые системы, поддерживающие поиск на русском языке, не поддерживают русскую морфологию. В русскоязычной части сети Интернет работают около двух десятков поисковых систем, но подавляющие большинство пользователей работает лишь с несколькими, подробно остановимся на самых крупных:
1.5.1 Yandex
Яндекс - На сегодня наиболее популярная поисковая система, ежемесячно к ней обращаются более 35 миллионов пользователей Русскоязычной части Интернета. Начала свою работу во второй половине 1997 года учитывая морфологию русского языка. История компании "Яндекс" началась в 1990 году с разработки поискового программного обеспечения в компании "Аркадия". За два года работ были созданы две информационно-поисковые системы - Международная Классификация Изобретений, 4 и 5 редакция, а также Классификатор Товаров и Услуг. Обе системы работали локально под DOS и позволяли проводить поиск, выбирая слова из заданного словаря, с использованием стандартных логических операторов. В1993 году "Аркадия" стала подразделением компании CompTek. В 1993-1994 годы программные технологии были существенно усовершенствованы благодаря сотрудничеству с лабораторией Ю. Д. Апресяна (Институт Проблем Передачи Информации РАН). В частности, словарь, обеспечивающий поиск с учетом морфологии русского языка, занимал всего 300Кб, то есть целиком грузился в оперативную память и работал очень быстро. С этого момента пользователь мог задавать в запросе любые формы слов.
Слово Яндекс придумал за несколько лет до этого один из основных и старейших разработчиков поискового механизма. "Яndex" означает "Языковой index", или, если по-английски, "Yandex" - "Yet Another indexer". За 4 года публичного существования Яndex возникли и другие толкования. Например, если в слове "Index" перевести с английского первую букву ("I" - "Я"), получится "Яndex".
В начале 1996 года был разработан алгоритм построения гипотез. Отныне морфологический разбор перестал быть привязан к словарю - если какого-либо слова в словаре нет, то находятся наиболее похожие на него словарные слова и по ним строится модель словоизменения. В это время Интернет в России только начинался. Еще через полгода стало очевидно, что ничто не отделяет CompTek от создания собственной глобальной поисковой машины. Объем Рунета составлял тогда всего несколько гигабайт. Осенью 1997 года был открыт Yandex.Ru.
Помимо поисковой системы, сегодня Яндекс - огромный портал с целым набором широко используемых сервисов, такими как каталог, Яндекс. деньги, и другие. Официально поисковая машина Yandex.Ru была анонсирована 23 сентября 1997 года на выставке Softool. Основными отличительными чертами Yandex.Ru на тот момент были проверка уникальности документов (исключение копий в разных кодировках), а также ключевые свойства поискового ядра Яндекс, а именно: учет морфологии русского языка (в том числе и поиск по точной словоформе), поиск с учетом расстояния (в том числе в пределах абзаца, точное словосочетание), и тщательно разработанный алгоритм оценки релевантности (соответствия ответа запросу), учитывающий не только количество слов запроса, найденных в тексте, но и "контрастность" слова (его относительную частоту для данного документа), расстояние между словами, и положение слова в документе. Сегодня Яндекс имеет внутри мощный поисковый робот, позволяющий производить поиск по самым различным критериям.
1.5.2 Rambler
Rambler - Старейшая поисковая система российского Интернет, запущена в 1996 году, на сегодня - вторая по популярности с обращением более 25 миллионов посетителей в месяц. Помимо поисковой системы, сегодня Рамблер - один из крупнейших порталов Русскоязычной части Интернета с большим набором широко известных сервисов, таких как каталог Рамблер, Рамблер-почта, Рамблер-ICQ или Рамблер-ТВ. По сути сегодня Рамблер - больше, чем просто поисковая система и набор сервисов, это крупная медиагруппа. Поисковая машина "Рамблер" начала работу в октябре 1996 года, на стартовом этапе содержала всего 100 тысяч документов. "Рамблер" не был первой отечественной поисковой системой, однако в первый год своего существования (когда весь русский веб с приемлемой степенью правдоподобия индексировался "Рамблером", "Апортом", "Русской поисковой машиной", а также шведской и калифорнийской AltaVista) вынес основной груз поисковых запросов. Вторая версия "Рамблера" начала разрабатываться летом 2000 года, в марте нынешнего года приняла достаточно законченные очертания. В нее были введены функции, давно уже имевшиеся в конкурирующих системах. Она учитывает координаты слов, обучена строгой и нечеткой морфологии, связывает поиск с каталогом, в качестве которого используется Top100 (http://top100.rambler.ru/), группирует результаты поиска по сайтам, ищет по числам. Достаточно удачная архитектура продукта позволяет "Рамблер" иметь для поисковика количество серверов в 2 раза меньшее, чем у "Яндекса", и в 3 раза меньшее, чем у "Апорта".
1.5.3 Апорт
Апорт- Третья популярности на сегодня поисковая система с обращением более 16 миллионов посетителей в месяц. Апорт позволяет пользователям осуществлять полнотекстовый поиск документов c учетом морфологии русского языка в запросах. Поисковая система построена на основании новейших достижений в области информационного поиска и использует уникальные алгоритмы сортировки найденных результатов. Разнообразные специализированные поиски (Знакомства, Товары, Новости, Рефераты, MP3 и др.) дают пользователям дополнительные возможности находить различную информацию в Сети. В поисковую машину интегрирован один из крупнейших в Русскоязычной части Интернет каталогов Интернет-ресурсов "Апорт-каталог".
Поисковая машина "Апорт" была впервые продемонстрирована в феврале 1996 года на пресс-конференции "Агамы" по поводу открытия "Русского клуба". Тогда она искала только по сайту russia.agama.com. Потом она начала искать по четырем, потом по шести серверам... Короче, день рождения и фактический старт системы сильно "размазались" по времени, а официальная презентация "Апорта" состоялась только 11 ноября 1997 года. К тому времени в его базе был проиндексирован первый миллион документов, расположенных на 10 тысячах серверов. Создателем системы выступила компания "Агама" - разработчик программного обеспечения для платформы Windows, главным из которых являлся корректор орфографии "Пропись". Лингвистические разработки "Агамы" использовались при создании поисковой машины, в которой, скажем, в отличие от "Рамблер", изначально учитывалась морфология слов и осуществлялась по желанию клиента проверка орфографии запроса.
Важнейшими свойствами первой версии "Апорта" являлся перевод запроса и результатов поиска на английский язык и обратно, а также реконструкция всех проиндексированных страниц из собственной базы (что означает возможность просмотра страниц, уже несуществующих в оригинале).
Апорт 2000" стал первой российской поисковой машиной, практически реализовавший две базовых технологии американской поисковой машины Google. Первая - учет "ранга страницы" (Page Rank), который характеризует ее популярность (вычисляется по количеству ссылок на ресурс из внешнего Интернета: вес ссылки с популярного сайта выше, чем вес ссылки с менее популярного; ссылки, включающие слова запроса, имеют больший вес, чем, скажем, слово "здесь"). Вторая - обработка запроса, ориентируясь на HTML-код страницы. В "Апорт 2000" учитывается также вхождение слов запроса в URL. Среди недокументированных особенностей - больший приоритет сайтам, получившим высшую и элитную лигу в каталоге AtRus.
Можно отметить и то, что "Апорт" первым устроил поиск по новостным лентам (какие бы ложные сведения о приоритете "Яндекса" в этом сервисе не распускал в свое время Internet.ru). И, наконец, еще одно первенство "Апорта" - использование платной нулевой строки в выдаче (кстати, "Апорт" первым среди наших поисковиков начал покупать такой сервис у AltaVista, которая за небольшую плату выдавала его ссылку первой при запросе "Russian Search"). Однако в "Апорте" нельзя купить не нулевое, а просто более высокое место для своего сайта в результатах поиска. Пользователи "Апорта" (в отличие завсегдатаев "Яндекса") мало пользуются расширенным поиском (на 8000 загрузок простой страницы приходится 300 вызовов страницы "Расширенный поиск").
Организация масштабируемости в архитектуре "Апорт 2000" такова, что можно дробить поисковую базу "Апорта" на несколько отдельных баз, каждый маленький "Апорт" работает на своем компьютере. "Апорт 2000" считает, что весь Интернет поделен на фрагменты. После проведения поиска по этим фрагментам, пользователю интегрируется и выдается общий ответ. Добавлять новые маленькие "апортики" можно путем не очень сложной процедуры. В случаях аварий отдельных машин выдаются несколько отличные от штатных интегральные результаты, что мы можем время от времени наблюдать.
1.5.4 Mail.ru
Национальная почтовая служба Mail.ru - это не только поисковая система но и один из крупнейших порталов российского Интернета. Ежедневная аудитория Mail.ru - более 5 миллионов пользователей. Общее число регистраций со дня основания около 60 миллионов. Mail.ru - самый быстроразвивающийся российский Интернет-ресурс. Через почтовые ящики Mail.ru ежедневно проходит более 25 миллионов писем. Mail.ru занимает лидирующую позицию среди бесплатных почтовых сервисов, предоставляя своим пользователям почтовый ящик неограниченного размера с защитой от спама и вирусов, переводчиком, проверкой правописания, архивом для хранения фотографий и многое другое.
В 1998-м году программисты, работающие в питерском офисе американской софтверной компании DataArt, создали новое ПО для почтового веб-сервера, которое в дальнейшем предполагалось продавать западным компаниям. Чтобы протестировать сервис, его временно выложили в открытый доступ для российских пользователей, а сервис вдруг стал стремительно набирать популярность.
20 февраля 2001 года произошло слияние двух крупных игроков российского Интернет-рынка, компаний Port.ru и netBridge под брендом Port.ru. В результате объединения родилась компания, которая сразу заняла лидирующие позиции среди российских Интернет - холдингов по доле рынка и охвату аудитории.
· Первоочередная задача любой поисковой системы - доставлять людям именно ту информацию, которую они ищут.
· Основные характеристики поисковых систем:
1. Полнота
2. Точность
3. Актуальность
4. Скорость поиска
5. Наглядность
В состав поисковой системы входят компоненты:
1. Модуль индексирования
2. База данных
3. Поисковый сервер
Подводя итог можно сказать что, как правило, несмотря на обилие поисковых систем, пользователь предпочитает обращаться к услугам лишь одной - двух из них (точно также как при обилии газет или новостных сайтов мы регулярно просматриваем лишь некоторые, привычные и любимые). Самой популярной поисковой системой в мире является Google. Но по оценкам аналитиков, на просторах бывшего СССР чаше используется Яндекс.
Глава II. Обработка информации в маркетинговом исследовании
Маркетинговые исследования - форма исследования, которая фокусируется на понимании поведения, желаний и предпочтений потребителей в диктуемой рынком экономике. Маркетинговое исследование предполагает сбор и анализ данных, которые требуются для маркетинговой деятельности. Обработка информации полученной в ходе маркетингового исследования возможна при помощи комплекта программ Microsoft Office.
2.1 Текстовый процессор Microsoft Word
В программе MsWord кроме обработки текстовой информации осуществляется описание технологического процесса исследования, цели, методов которыми оно осуществлялось, а также основные результаты (аналитическая часть) исследования. После ввода текстовой информации, в программе возможно форматирование текста (изменение шрифтов текста, полей, абзаца, размера текста, а также вставка диаграмм, картинок, таблиц и многие другие функции необходимые для визуального представления информации полученной в ходе маркетингового исследования).
2.2 Табличный редактор Excel
Табличный процессор Excel позволяет выполнять вычисления с помощью формул и встроенных функций, строить диаграммы и графики по результатам вычислений, анализировать данные и работать со списками в таблицах. Самый эффективный метод представления данных с помощью графика. Он позволяет увидеть те закономерности, которые не всегда усматриваются в таблице чисел.
В программе Ms Excel создается база данных и осуществляется ввод и обработка числовой информации полученной в ходе исследования. По этим данным в дальнейшем осуществляется построение графиков и таблиц, для обеспечения большей наглядности полученной информации. Диаграммы и гистограммы делаются по всем вопросам представленным в анкете.
2.3 Редактор Microsoft Power Point
Программа Ms Power Point предназначена для визуального представления результатов исследования, проведения презентаций с использованием слайдов. Слайды могут содержать информация любого типа и использовать документы других приложений MS Office. Power Point также используется для создания презентации по маркетинговому исследованию, после обработки информации в текстовых и числовых редакторах Основная информация полученная в ходе исследования размещается на слайдах, тем самым описывается в вкратце ход, методика, цели и результаты исследования, также возможна вставка таблиц, диаграмм и добавление анимации и звука к слайдам для большей наглядности представленных данных.
Глава III . Организация рабочего места оператора ЭВМ
3.1 Общие требования безопасности
3.1.1 К самостоятельной работе с ЭВМ допускаются лица прошедшие специальную подготовку, в том числе на III группу электробезопасности, обязательный медицинский осмотр и инструктаж по охране труда, не имеющие противопоказаний по состоянию здоровья. Женщины со времени установления беременности и в период кормления ребенка грудью к выполнению всех видов работ, связанных с использованием ЭВМ, не допускаются.
3.1.2 Пользователи ЭВМ должны соблюдать правила внутреннего трудового распорядка, установленные режимы труда и отдыха.
3.1.3 При работе с ЭВМ возможно воздействие на работающих следующих опасных и вредных производственных факторов:
Ионизирующие и неионизирующие излучения видеотерминалов;
Поражение электрическим током при работе на оборудовании без защитного заземления, а также со снятой задней крышкой видеотерминала;
Зрительное утомление, а также неблагоприятное воздействие на зрение мерцаний символов и фона при неустойчивой работе видеотерминала, нечетком изображении на экране.
3.1.4 При работе с ЭВМ необходимо использовать защитные экраны.
3.1.5 Помещение с ЭВМ должно быть оснащено медицинской аптечкой первой помощи, системой кондиционирования воздуха или вытяжной вентиляцией.
3.1.6 Пользователи ЭВМ обязаны соблюдать правила пожарной безопасности, знать места расположения первичных средств пожаротушения. Помещение с ЭВМ должно быть оснащено двумя углекислотными огнетушителями и автоматической системой пожарной сигнализации.
3.1.7 О каждом несчастном случае с работником пострадавший или очевидец несчастного случая обязан немедленно сообщить администрации учреждения. При неисправности оборудования прекратить работу и сообщить администрации учреждения.
3.1.8 В процессе работы пользователи ЭВМ должны соблюдать правила использования средств индивидуальной и коллективной защиты, соблюдать правила личной ни иены, содержать в чистоте рабочее место.
3.1.9 Лица, допустившие невыполнение или нарушение инструкции по охране труда, привлекаются к дисциплинарной ответственности в соответствии с правилами внутреннего трудового распорядка и, при необходимости, подвергаются внеочередной проверке знаний норм и правил охраны труда.
3.2 Требования безопасности перед началом работы
3.2.1 Тщательно проветрить помещение с ЭВМ, убедиться, что микроклимат в помещении находится в допустимых пределах: температура воздуха в холодный период года - 22-24°С, в теплый период года -23-25°С, относительная влажность воздуха - 40 - 60 %.
3.2.2 Убедиться в наличии защитного заземления оборудования, а также защитных экранов видеомониторов.
3.2.3 Включить видеомониторы и проверить стабильность и четкость изображения на экранах.
3.3 Требования безопасности во время работы
3.3.1 При paботе с ЭВМ значения визуальных параметров должны находиться в пределах оптимальною диапазона.
3.3.2 Клавиатуру располагать на поверхности стола на расстоянии 100-300 мм от края, обращенного к пользователю.
3.3.3 Тетрадь для записей располагается на подставке с наклоном 12-15° на расстоянии 55 - 65 см от глаз, которая должна быть хорошо освещена.
3.3.4 При работающем видеотерминале расстояние от глаз до экрана должно быть 0,6 - 0,7 м, уровень глаз должен приходиться на центр экрана или на 2/3 его высоты.
3.3.5 Изображение на экранах видеомониторов должно быть, с обильным, ясным и предельно четким, не иметь мерцаний символов и фона, на экранах не должно быть бликов и отражений светильников, окон и окружающих предметов.
3.3.6 Не работать с ЭВМ без защитных экранов.
3.3.7 Суммарное время непосредственной работы с ВДТ и ПЭВМ в течение рабочего дня должно быть не более 6 часов, для преподавателей высших и средних специальных учебных заведений, учителей общеобразовательных школ - не более 4 часов в день.
3.3.8 Продолжительность непрерывной работы с ЭВМ без регламентированного перерыва не должна превышать 2-х часов. Через каждый час работы следует делать регламентированный перерыв продолжительностью 15 мин.
3.3.9 Во время регламентированных перерывов с целью снижения нервно-эмоционального напряжения, утомления зрительного анализатора, устранения влияния гиподинамии и гипокинезии, предотвращения развития познотонического утомления следует выполнять комплексы упражнений для глаз, физкультурные минутки и физкультурные паузы.
3.4 Требования безопасности в аварийных ситуациях
3.4.1 В случае появления неисправности в работе видеотерминала выключить его, сообщить об этом администрации учреждения. Работу продолжать только после устранения возникшей неисправности.
3.4.2 В случае возникновения у пользователя зрительного дискомфорт и других неблагоприятных субъективных ощущений следует ограничить время работы ЭВМ, провести коррекцию длительности перерывов для отдыха или провести смену деятельности на другую, не связанную с использованием ЭВМ.
3.4.3 При поражении пользователя электрическим током немедленно отключить электросеть, оказать первую помощь пострадавшему, при необходимости вызвать скорую помощь (03) и дождаться медиков.
Заключение
По итогам сделанной мной работы я могу заключить что; поисковые системы уже давно стали неотъемлемой частью Интернета. Поисковые системы сейчас - это огромные и сложные механизмы, представляющие собой не только инструмент поиска информации, но и заманчивые сферы для бизнеса.
По моему мнению, самой лучшей иностранной поисковой системой является Google, так как для меня основное значение имеет точность и полнота предоставляемых данных. Но можно заключить также что, каждая поисковая система будь то Российская или зарубежная предоставляет различные возможности поиска, из различных баз данных, поэтому сказать точно какой именно лучше пользоваться было бы не правильно. Поэтому для удобства поиска и полноты информации следует пользоваться несколькими поисковиками вводя в них нужные запросы. По моему мнению, из многих Российских поисковиков выделяются Яндекс и Рамблер, для них характерно постоянное обновление баз данных что, обеспечивает именно актуальность и точность предоставляемой информации.



